„ Sehr gute Beratung bei der Konzeption unserer App. " Ayse
„ Sehr gute Beratung bei der Konzeption unserer App. " Ayse





Die Verwendung von IP-Adressen ist das wichtigste Mittel, um Geräte in die Lage zu versetzen, sich gegenseitig zu lokalisieren und eine End-to-End-Kommunikation im Internet aufzubauen. Jedes Endgerät in einem Netzwerk muss mit einer IP-Adresse konfiguriert werden. Beispiele für Endgeräte sind diese:
Die Struktur einer IPv4-Adresse wird als punktierte Dezimalnotation definiert und durch vier Dezimalzahlen zwischen 0 und 255 dargestellt. IPv4-Adressen werden einzelnen Geräten zugewiesen, die an ein Netzwerk angeschlossen sind.
IP bezieht sich in diesem Artiekl sowohl auf das IPv4- als auch auf das IPv6-Protokoll. IPv6 ist die jüngste Version von IP und ersetzt das übliche IPv4 Protokoll. Mit der IPv4-Adresse ist auch eine Subnetzmaske erforderlich. Eine IPv4-Subnetzmaske ist ein 32-Bit-Wert, der den Netzwerkteil der Adresse vom Hostteil unterscheidet. In Verbindung mit der IPv4-Adresse bestimmt die Subnetzmaske, zu welchem Subnetz das Gerät gehört.
Betrachten Sie als Beispiel die IPv4-Adresse 192.168.100.2, die Subnetzmaske 255.255.255.0 und das Standard-Gateway 192.168.100.1, die einem Host zugewiesen sind. Die Standard-Gateway-Adresse ist die IP-Adresse des Routers, den der Host für den Zugriff auf entfernte Netzwerke, einschließlich des Internets, verwendet.
Halten wir also fest: Eine IPv4-Adresse ist eine hierarchische 32-Bit-Adresse, die sich aus einem Netzwerkteil und einem Hostteil zusammensetzt. Bei der Bestimmung des Netzwerkteils gegenüber dem Hostteil müssen Sie den 32-Bit-Stream betrachten.
Die Bits innerhalb des Netzwerkteils der Adresse müssen für alle Geräte, die sich im gleichen Netzwerk befinden, identisch sein. Die Bits innerhalb des Hostteils der Adresse müssen eindeutig sein, um einen bestimmten Host in einem Netzwerk zu identifizieren. Wenn zwei Hosts dasselbe Bitmuster im angegebenen Netzwerkteil des 32-Bit-Streams haben, befinden sich diese beiden Hosts im selben Netzwerk.
Aber woher wissen die Hosts, welcher Teil der 32-Bits das Netzwerk und welcher den Host identifiziert? Das ist die Rolle der Subnetzmaske.
IPv4-Adressen beginnen als Binäradressen, eine Reihe von nur 1 und 0. Diese sind schwer zu verwalten, so dass Netzwerkadministratoren sie in Dezimalzahlen umwandeln müssen. Dieses Thema zeigt Ihnen einige Möglichkeiten, dies zu tun.
Binär ist ein Nummerierungssystem, das aus den Ziffern 0 und 1, den sogenannten Bits, besteht. Im Gegensatz dazu besteht das dezimale Zahlensystem aus 10 Ziffern, die aus den Ziffern 0 - 9 bestehen.
Binär ist für uns wichtig zu verstehen, da Hosts, Server und Netzwerkgeräte binäre Adressierung verwenden. Insbesondere verwenden sie binäre IPv4-Adressen, um sich gegenseitig zu identifizieren.
Fassen wir zusammen:
Jede Adresse besteht aus einer Zeichenfolge von 32 Bit, die in vier Abschnitte, die Oktette genannt werden, unterteilt ist. Jedes Oktett enthält 8 Bits (oder 1 Byte), die durch einen Punkt getrennt sind.
Betrachten wir die IPv4-Adresse 192.168.100.2; 11000000.10101000.01100100.00000010. Die Standard-Gateway-Adresse wäre beispielsweise die Schnittstelle 192.168.100.1; 11000000.10101000.01100100.0000000001.
Binär funktioniert gut mit Hosts und Netzwerkgeräten. Allerdings ist es für Menschen sehr schwierig, damit zu arbeiten.
Diese Artikelserie wird sich daher mit folgenden Inhalten auseinandersetzen und ins Detail gehen:
In der Informationstechnolgie kommt man früher oder später nicht umhin, sich mit den Begriffen wie Bridge, Hub, Repeater, Router, Switch etc. zu beschäftigen, um sich ein Bild von der Funktionsweise und dessen Nutzen zu machen. Deshalb ein kleiner Überblick über die genannten Begriffe und ein Übersicht über die Charakteristika.
Diese hat die Aufgabe, Netze auf den Teilschichten MAC oder LLC der OSI-Schicht 2 - Data Layer, Datenübertragungsschicht - zu verbinden (MAC-Level-Bridge). Hierbei gilt es zu beachten, dass die Netze unterschiedliche Topologien besitzen können.
Hierbei spricht man im engeren Sinne von einem Sternkoppler oder auch Sternverteiler (Kabelkonzentrator), welcher die Verbindung eines Konzentrators mit einem Repeater ist, sogenannte Multiport-Repeater, wobei die Hubs die Repeater in vielen Bereichen ersetzt haben. Der Hub kann auch als Knotenpunkt gesehen werden, über den alle Daten laufen bzw. weitergeleitet werden, deshalb wird diese auch als "Konvergenz-Stelle" bezeichnet, da hier bei der Kommunitkation von Daten alles zusammenläuft.
Dieser erfüllt die Aufgabe, verschiedene Netze mit vollkommen gleichartigen Zugriffsweisen und Protokollen zu verbinden. Gleichzeitig reduziert der Repeater Signaldämpfungen sowie - verzerrungen und wird daher auch als Aufholverstärker bezeichnet. Selbstverständlich verbinden moderne Repeater ebenso völlig unterschiedliche Medien.
Diesbezüglich sei das Wort "Transparenz" erwähnt, da der Router autonom das Netz analysiert und somit auch Transparenz schafft. Zusätzlich auf Basis routbarer Protokolle, sucht er geeignete Wege im Netz. Darüber hinaus ist er in der Lage, sogenannte "Routingtabellen" zu erstellen, welche mit Wegetabellen in Verbindung zu bringen sind. Letztendlich vermittelt er einen zielgerichteten Austausch von Datenpaketen im Netz. Eine weitere Applikation des Routers spiegelt sich im Bridging Router - BRouter - wider: simpel gesprochen ist es ein Router mit integrierter Bridge.
In Bezug auf Netzübergängen sowie getrennten Netzwelten - logisch/physikalisch - dient es der Realisierung und kompletten Adaption davon. Diese erfolgt durch die Um- bzw. Übersetzung verschiedener Netze in folgenden Schritten:
1. Adressübersetzung
2. Übersetzung der Datenübertragungsgeschwindigkeit
3. Protokolladaption (Konvertierung oder Umschreibung)
Somit beziehen sich besondere Funktionsaufgaben auf die Schichten 3 - 7 und werden daher auch intelligente Schnittstellen genannt. Zuguterletzt sind die hohen Sicherheitsstandards als Möglichkeit zugute zu halten.
Ein Switch fungiert wie eine Brdige, aber mit mehreren Zugängen für Rechner sowie Netze. Damit ist auch eine parallele Wandlung von Daten zwischen den unterschiedlichen Switchzugängen möglich. Außerdem besteht die Möglichkeit, eine Punkt-zu-Punkt-Geräte-Verbindungen herzustellen. Nicht zwangsläufig aber oft ist dieser ein Hardwareprodukt. Hierbei existieren sogenannte Layer-Switches, welche in folgende Typen unterteilt werden:
Layer 1-Switches: Keine Adressauswahl (Hub-System).
Layer 2-Switches/Layer 2/3-Switches: Über Adresstabellen automatisiert, werden diese durch die Zieladressen der Datenpakete generiert. Dabei wird durch die in den Datenpaketen enthaltenen MAC-Adressen nötige Information entnommen.
Layer 3-Switches: Verabreitet auch IP-Ardressen, da es sich auf der 3. Schicht befindet bzw. bewegt.
Der Switch ist in der Lage, im Gegensatz zum Hub, gezielt weiterzuleiten und zu entscheiden, wohin die Daten fließen sollen. Somit kann man den Switch als intelligent betrachten und den "weniger Schlauen" als Hub, da dieser an alles sendet.
Durchleitrate (Forwarding Rate): Pakete pro Sekunde
Filterrate (Filter Rate): Bearbeitete Paketanzahl pro Sekunde
Adressanzahl: Verwaltete (MAC-)Adressen
Backplanedurchsatz: Transportkapazität auf den Vermittlungsbussen
Store-and-Forwarding: Ein Datenpaket wird vollends über einen Port eingelesen und erst dann wird die Adresse verarbeitet, ein einfaches und sicheres Verfahren, mit einer vollständigen Fehlerüberprüfung und selbstständigem Verwerfen von fehlerhaften Paketen.
Nach dem Einlesen des Steuerkopfes der Datenpakete, erfolgt die Auswertung der Adresse. Gleichzeitig werden Nutzinformationen notiert bzw. aufgenommen und dadurch verringert sich die Latenzzeit, wobei immer noch Datenkollisionen möglich sind.
Eine Datenweitergabe wird nach den ersten 72 Bytes initiiert. Moderne Switches realisieren alle 3 Funktionsprinzipien zugleich (adaptives Switching, Error-Free-Cut-Through). Je nach Situation wird das optimale Verfahren angewendet.
Dieser Artikel beschäftigt sich mit dem Thema OSPF (Open Shortest Path First), wobei hier auf den Einzelbereich und Mehrbereich eingegangen wird.
OSPFv2 wird nur für IPv4-Netzwerke und OSPFv3 nur für IPv6-Netzwerke verwendet. Der primäre Fokus dieses Themas liegt auf OSPFv2 mit einem Bereich.
OSPF ist ein Link-State-Routing-Protokoll, welches als Alternative für das Distanzvektor-Routing-Informationsprotokoll (RIP) entwickelt wurde. Zu damaliger Zeit, im Kontext des Netzwerks und des Internets, war RIP ein hinnehmbares Routing-Protokoll.
Die Abhängigkeit des RIP, von der Anzahl der Hops als einzige Metrik zur Bestimmung der besten Route, kristallisierte sich jedoch schnell als Problematik heraus.
Unter Verwendung der Hop-Anzahl lässt sich in komplexen Netzwerken mit diversen Pfaden unterschiedlicher Geschwindigkeit suboptimal skalieren.
OSPF bietet gegenüber RIP immense Vorteile, da es eine schnellere Konvergenz bietet und sich auf viel größere Netzwerkimplementierungen skalieren lässt. OSPF ist ein Link-State-Routing-Protokoll, das das Konzept von Bereichen nutzt. Ein Netzwerkadministrator kann die Routingdomäne in verschiedene Bereiche unterteilen, um den Routing-Aktualisierungsverkehr zu steuern. Ein Link ist hier klassisch eine Schnittstelle auf einem Router.
Zum Netzwerksegment gehört auch der Begriff „Verbindung“, welcher auch Teil des Hiesigen ist und zwei Router verbindet. Somit lässt sich zum Beispiel ein Stub-Netzwerk über ein Ethernet-LAN verbinden, welches wiederum mit einem einzelnen Router Verbindung hält.
Der Begriff des Verbindungsstatus resultiert aus der Information über einen Status. Alle Verbindungsstatusinformationen umfassen das Netzwerkpräfix, die Präfixlänge und die Kosten.
Alle Routing-Protokolle haben homologe Komponenten. All diese Komponenten verwenden Routing-Protokollnachrichten, um Routeninformationen auszutauschen.
Beim Aufbau von Datenstrukturen, welche mithilfe eines Routing-Algorithmus verarbeitet werden, sind diese Nachrichten hilfreich.
Router, auf denen OSPF ausgeführt wird, tauschen Nachrichten aus, um Routing-Informationen mithilfe von fünf Pakettypen zu übermitteln. Diese Pakete werden gegliedert in:
Diese Pakete werden verwendet, um benachbarte Router zu erkennen und Routing-Informationen auszutauschen, um genaue Informationen über das Netzwerk zu erhalten.
OSPF-Nachrichten werden zum Erstellen und Verwalten von drei OSPF-Datenbanken wie folgt verwendet:
Diese Tabellen enthalten eine Liste benachbarter Router zum Austausch von Routing-Informationen. Diese Tabellen werden im RAM gespeichert und verwaltet.
Anhand von Berechnungsergebnissen erstellt der Router die Topologietabelle, die auf dem SPF-Algorithmus (Dijkstra Shortest-Path First) basieren. Der SPF-Algorithmus wiederum basiert auf den kumulierten Kosten zum Erreichen eines Ziels.
Der SPF-Algorithmus erstellt einen SPF-Baum, indem jeder Router an der Wurzel des Baums platziert und der kürzeste Pfad zu jedem Knoten berechnet wird. Der SPF-Baum wird dann verwendet, um die besten Routen zu berechnen. OSPF platziert die besten Routen in der Weiterleitungsdatenbank, aus der die Routing-Tabelle erstellt wird.
Um die Routing-Informationen beizubehalten und einen Konvergenzstatus zu erreichen, führen OSPF-Router einen allgemeinen Routing-Prozess für den Verbindungsstatus durch.
Bei OSPF werden die Kosten verwendet, um den besten Pfad zum Ziel zu definieren. Dabei existieren Routing-Schritte für den Verbindungsstatus und das Ganze von einem Router ausgeführt:

Diese Netzwerktechnologie basiert auf der Funktechnik und nutzt somit für die Datenübertragung die Luft als Kanal. Jedoch ist die Annahme bzw. These im Kontext der einzigen Möglichkeit der Datenübertragung in Bezug auf Luft als solche eine irrige und somit falsche. Der pyhsikalischen Grundlage nach ist es eine elektromagnetische Welle, welche wiederum an eine elektrische und magnetische Transversalwelle gekoppelt ist, die im freien Raum bzw. im Raum-Zeit-Kontinuum übertragen wird. Daher können diese elektromagnetische Wellen auch ohne das Medium Luft übertragen werden, wie z. B. im Weltall, ergo im Vakuum.
Daraus resultiert die Möglichkeit, sich nicht erschlossene Regionen oder Örtlichkeiten ohne die Verlegung von Kabeln kostengünstig zu vernetzen oder diese Technologie theoretisch auch im Weltraum zu benutzen.
Wir beschränken uns hier jedoch auf den irdischen Teil.
Wie bei den drahtgebundenen Netzwerken werden auch diese in folgende Segmente unterteilt nach IEEE (Institute of Electrical and Electronics Engineers):
IEEE 802.15.3 UWB (Ultra-Wide Band)=High Speed Wireless PAN; bis zu 1000 Mbit/s
Grundlegend wird bei IEEE 802.11 das CSMA/CA-Verfahren (Carrier Sense Multiple Access/Collision Avoidance) genutzt, was der Kollisionsvermeidung dient.
Im nächsten Artikel befassen wir uns mit dem WLAN-Einsatz sowie der WLAN-Sicherheit, welche unabdingbar und gesetzlich vorgeschrieben, aber auch abgesehen davon, sinnvoll und empfehlenswert ist.
In unserem ersten Artikel haben wir uns über die die vier Eigenschaften wie Vertraulichkeit, Integrität, Verfügbarkeit und Authentizität befasst sowie mit der symmetrischen Verschlüsselung. Im zweiten Teil unserer Artikelserie beschäftigen wir uns mit der asymmetrischen Verschlüsselung, sowie eine Verschlüsselungstechnik die darauf basierend aufgebaut ist.
Bei der asymmetrischen Verschlüsselung hingegen bedienen sich die Teilnehmer eines Schlüsselpaares, welches aus einem Puplic Key (öffentlicher Schlüssel) und einem Private Key (privaten Schlüssel) besteht. Diese hängen mathematisch zusammen.
Wie der Name Puplic Key schon sagt, ist dieser Schlüssel für alle frei zugänglich, nicht jedoch der Private Key, dieser ist optional nur dem Besitzer bekannt.
Somit ergibt sich, dass eine Nachricht, welche mit dem Private Key verschlüsselt wurde, nur mit dem Puplic Key entschlüsselt werden kann und umgekehrt; eine Nachricht, welche mit dem Puplic Key verschlüsselt wurde, kann nur noch mit dem dazugehörigen Private Key entschlüsselt werden.
Anwendung findet dies bei dem Schutzziel der Integrität, die digitale Signaturen verwendet.
Bei einer digitalen Signatur wird ein sogenannter Hash-Wert erzeugt. Ein Hashwert besitzt eine feste Länge und bedient sich diverser Hashfunktionen.
Eine unendlich große Menge wird auf eine endliche abgebildet aber gilt als kollisionsresistent, zumindest für menschliche Verhältnisse. Es kann also nicht sein, dass 2 verschiedene Hashwerte auf ein gleiches Produkt zutreffen, da dies sonst nicht mehr sicher wäre.
Eine Hashfunktion ist eine Einwegfunktion und kann daher nicht rückwärts auf den eigentlichen Wert schließen.
Bildet man von einem Dokument einen Hashwert und verschlüsselt das Dokument mit dem erzeugten Hashwert nun mit seinem Private Key, kann jeder mit dem freizugänglichen Puplic Key, das Dokument damit entschlüsseln und den Hashwert vergleichen. Sollte dieser gleich sein, kann man sich sicher sein, dass dieser zu dem dazugehörigen Private Key gehört und die Signatur korrekt ist.
Digitale Signaturen bedeuten daher - sofern die Hashwerte übereinstimmen - dass der Puplic Key zu dem Private Key gehört und Daten nicht manipuliert wurden.
Es sagt nicht unbedingt aus, dass mein Gegenüber wirklich derjenige ist, der er vorzugeben scheint. Dies regeln die Zertifikate und behandelt das Schutzziel Authentizität.
Der größte Vorteil der asymmetrischen Verschlüsselung besteht darin, dass der Schlüsseltausch entfällt.
Der größte Nachteil besteht darin, dass es ein extrem langsames und kompliziertes Verfahren ist.
RSA resultiert aus den Anfangsbuchstaben der Nachnamen von seinen Erfindern: Rivest, Shamir und Adleman. Das Verfahren wurde 1977 entwickelt und gilt bis heute als sicher.
Die RSA-Verschlüsselung bedient sich der Einwegfunktionen und lässt sich in eine Richtung ganz leicht berechnen(verschlüsseln), jedoch rückwärts (entschlüsseln ohne Schlüssel) ist ein immenser echter Rechenaufwand nötig, da hier faktorisiert werden muss, die Zerlegung von n in die Faktoren p und q.
Beim RSA-Verfahren ist die Zahl n das Produkt aus zwei ver-schiedenen Primzahlen p und q.
Öffentlich bekannt jedoch ist nur die Zahl n, nicht aber die beiden Faktoren p und q, aus denen sich n zusammensetzt.
Eine exakte Beschreibung des Verfahrens finden Sie in einem bereits verfassten Beitrag zum Thema: RSA Verschlüsselung.
Selbstverständlich lassen sich auch diverse Beschreibungen und mathematische Berechnungen im Internet oder in Primär- sowie Sekundärliteratur dazu finden.
Als IT-Service in München und Umgebung bieten wir KMUs sowie Privatpersonen die Möglichkeit von uns über Verschlüsselungstechniken und rund um das Thema IT Sicherheit beraten zu lassen. Ein Recht auf geschützte und unabhörbare Kommunikation von zwei Endpunkten via Internet oder Telefon sollten alle haben. Wir helfen Ihnen bei der Planung und Umsetzung von IT Lösungen, wenn es um den Schutz um Firmeninterna oder ganz einfach um Ihre Privatsphäre geht. Rufen Sie uns an unter der Rufnummer 0176 / 75 19 18 18 oder schreiben Sie uns ganz einfach unter Diese E-Mail-Adresse ist vor Spambots geschützt! Zur Anzeige muss JavaScript eingeschaltet sein!

Jeder kennt sie, jeder hat sie und die wenigsten wissen, was genau eine Firewall überhaupt macht. Denn häufig wird die Firewall mit anderen Sicherheitssoftware verwechselt oder gleichgesetzt. Wir klären auf, was eine Firewall ist, für was sie zuständig ist und welche Typen es gibt.
Firewalls sind Software. Sie stellen ein Sicherungssystem dar, das dafür sorgt, dass ein Rechnernetzwerk oder einzelne Computer vor unerwünschtem Netzwerkzugriffen geschützt wird. Dabei ist die Firewall meist ein Teil eines bestimmten Sicherheitskonzepts.
Eine Firewall dient dazu, den Netzwerkzugriff aus dem Netzwerk auf den PC beziehungsweise vom PC auf das Netzwerk zu limitieren. Sie überprüft und überwacht die Absender und Ziele sowie die verwendeten Dienste. Dabei verwendet die Software eine Reihe festgelegter Regeln, um zu entscheiden, welche Datenpakete durchgelassen oder aufgehalten werden.
Entgegen landläufiger Meinung dient eine Firewall nicht dazu, Angriffe (beispielsweise aus dem Internet oder durch Hacker) zu erkennen und Gegenmaßnahmen einzuleiten. Sie ist für die Regelung der Netzwerkkommunikation zuständig und kann damit der Abwehr von Angriffen dienen, erkennt diese jedoch nicht und entscheidet auch nicht über die Gegenmaßnahmen. Dies ist die Aufgabe von sogenannten IDS-Modulen (Intrusion Detection System), die zwar auf einer Firewall aufbauen, aber nicht zu dieser gehören.
Da Firewalls nach vorgegebenen Regeln entscheiden, welche Programme und Dienste auf das Netzwerk zugreifen dürfen, kann sie die Ausnutzung einer Sicherheitslücke nicht verhindern, wenn diese Programme oder Dienste explizit darauf zugreifen dürfen. Daraus folgt, dass die beste Firewall nichts bringt, wenn der User jedem Programm gestattet, auf das Netzwerk zuzugreifen. Hier ist also eine Sensibilisierung im Umgang mit Internetdiensten und anderweitigen risikobehafteten Anwendungen von größter Wichtigkeit.
Eines der Haupteinfallstore für Angriffe aus dem Internet ist der Webbrowser, da der darauf ausgelegt ist, Daten oder Zugriffe aus dem Netzwerk zu erlauben. Würde man in den Firewalleinstellungen beispielsweise den Zugriff des Browsers auf das Internet untersagen, würde dieser zwar kein Risiko mehr darstellen, allerdings wäre seine eigentliche Funktion damit ebenfalls ausgeschaltet.
Um zu gewährleisten, dass der Browser auf das Internet zugreifen kann, aber trotzdem sicher ist, muss die Firewall also anders vorgehen, um potenziellen Gefahren entgegenwirken zu können. Beispielsweise kann von vornherein verhindert werden, dass bestimmte Elemente im Browser, die Sicherheitslücken enthalten oder Schadsoftware auf den Computer einschleusen könnten, aktiviert werden. Das gilt beispielsweise auch für JavaScripte, die häufig vom Browser nicht ausgeführt werden. Diese Einstellungen können in den gängigen Browsern allerdings auch eingestellt werden, sodass die Firewall diese Aufgabe nicht übernehmen muss.
Im Idealfall kann eine Firewall auf heimlich installierte Schadsoftware aufmerksam machen und sogar den Netzwerkzugriff dieser Malware unterbinden, allerdings hängt dies stark von der Vorgehensweise der Schadsoftware ab und wie geschickt sie ihre Tätigkeit verbergen kann.
Je nachdem, wo eine Firewall ausgeführt wird, unterscheidet man die persönliche und die externe Firewall voneinander. Während die persönliche Variante auf dem eigenen Rechner, also lokal läuft, agieren externe Firewalls vor dem Computer beziehungsweise dem Computernetzwerk.
Dabei ist zu beachten, dass diese Unterscheidung keinerlei Wertung enthält, welche der beiden Varianten in irgendeiner Form besser für bestimmte Situationen geeignet wäre als die andere. Vielmehr können die beiden Typen als Ergänzung zueinander angesehen werden.
Die persönliche Firewall wird lokal auf dem Anwender des Computers ausgeführt. Ihre Aufgabe besteht darin, ungewollte Zugriffe von außen zu unterbinden. Abhängig davon, welche Software verwendet wird, kann sie auch versuchen auf dem Computer laufende Anwendungen davon abzuhalten ohne die Erlaubnis des Nutzers mit der Außenwelt zu kommunizieren.
Viren, die auf den Computer zugreifen wollen, müssen dies über einen Sicherheitsfehler in einem der laufenden Netzwerkdienste tun. Dadurch, dass die Firewall durch die gesetzten Regeln diesen Netzzugriff verhindern kann, kann sie mitunter diese Viren abhalten. Außerdem kann die Firewall dadurch verhindern, dass von außen versucht wird, Schadsoftware auf dem Computer lokal zu installieren.
Allerdings bietet die persönliche Firewall keinen Schutz vor der Installation von Schadsoftware, die auf andere Art auf den Rechner gelangen konnte, sprich nicht über Sicherheitslücken im Netzwerk.
Wie bereits erwähnt ist die Unwissenheit des Anwenders mitunter ein großes Risikoproblem. So können durch Fehlbedienung die Funktionen der Firewall relativ einfach komplett ausgehebelt werden.
Wie der Name bereits suggeriert, wird die Firewall nicht lokal auf dem Computer des Anwenders ausgeführt, sondern auf externer Hardware. Dabei beschränkt sie die Verbindung zwischen zwei Netzwerken, etwa dem Heimnetzwerk des Anwenders und dem Internet.
Die externe Firewall ist hervorragend dafür geeignet, unerlaubte Zugriffe von außen auf das interne System zu unterbinden. Zu beachten ist, dass das interne System hier nicht nur ein einzelner Rechner sein kann (wie etwa bei einer persönlichen Firewall), sondern aus einem ganzen Netzwerk von Rechnern (beispielsweise einem Firmennetzwerk).
Oft wird für diese Form der Firewall auch der Begriff der Hardware-Firewall verwendet, was allerdings nicht bedeutet, dass diese ausschließlich auf Hardware basiert. Eine Firewall besteht immer auch als essenzieller Bestandteil aus einer Softwareanwendung. Der Begriff soll allerdings zum Ausdruck bringen, dass die Software auf extra dafür ausgelegter Hardware ausgeführt wird und nicht auf dem lokalen Rechner.
Externe Firewalls können als Vermittler zwischen zwei Netzwerken angesehen werden. So wird in einem sichtbaren oder einseitig transparenten Modus der Firewall nach außen hin nicht der interne Rechner, sondern die Firewall als mit dem externen Netzwerk verbundene Instanz angezeigt. Die Rechner des internen Netzwerkes senden also ihre Anfragen an die Firewall, die diese dann an das äußere Netzwerk (beispielsweise das Internet) weitergibt. Daraus resultiert, dass die Angriffe nicht direkt auf den lokalen Rechner gerichtet sind, sondern die Firewall diese quasi abfängt.
Auch Schadsoftware, die auf einem Rechner des internen Netzes installiert wurde, kann an diesem Prozedere nichts ändern. Der Rechner ist aufgrund der zwischengeschalteten Firewall nur aus dem internen Netzwerk, nicht aber von außen aufrufbar, wodurch kein direkter Zugriff von außen möglich ist.
Im zweiten Teil dieses Artikel werden die jeweiligen Vor- und Nachteile der beiden Firewall-Typen näher beleuchtet und Techniken der Firewall unter die Lupe genommen.
Sollten Sie Probleme mit Schadsoftware oder Ihrer Firewall haben, helfen wir Ihnen gerne mit jeglichen Computer-Problemen weiter! Unsere qualifizierten IT-Spezialisten kümmern sich in ganz München darum!
Wir freuen uns auf Sie!
Eine MAC-Adresse (Media-Access-Controll) ist eine eindeutige und in der Regel nicht veränderbare ID. Jedes Gerät mit einem Netzwerkadapter auf der Welt hat eine MAC-Adresse. Diese Adresse kann meistens auf Aufklebern auf den Geräten ausgelesen werden oder über die Kommandozeile. Je nachdem um welches Endgerät es sich hierbei handelt, sind die Wege unterschiedlich. Im Folgenden zeigen wir Ihnen die gängigsten Geräte auf denen ihr die eigene MAC-Adresse auslesen könnt.
Schritt 1: unter Windows 7:
Gehen Sie auf Start 
Abbildung 1 - Start Button von Windows 7
Abbildung 2 - Suchleiste
Schritt 2:
Geben Sie in die aufpoppende Suchleiste „CMD“ ein und klicken Sie auf ![]() . Anschließend öffnet sich das Terminal wie in Abbildung 3.
. Anschließend öffnet sich das Terminal wie in Abbildung 3.
Abbildung 3 - Terminal (CMD) von Windows
Geben Sie den Befehl „ipconfig /all“ ein
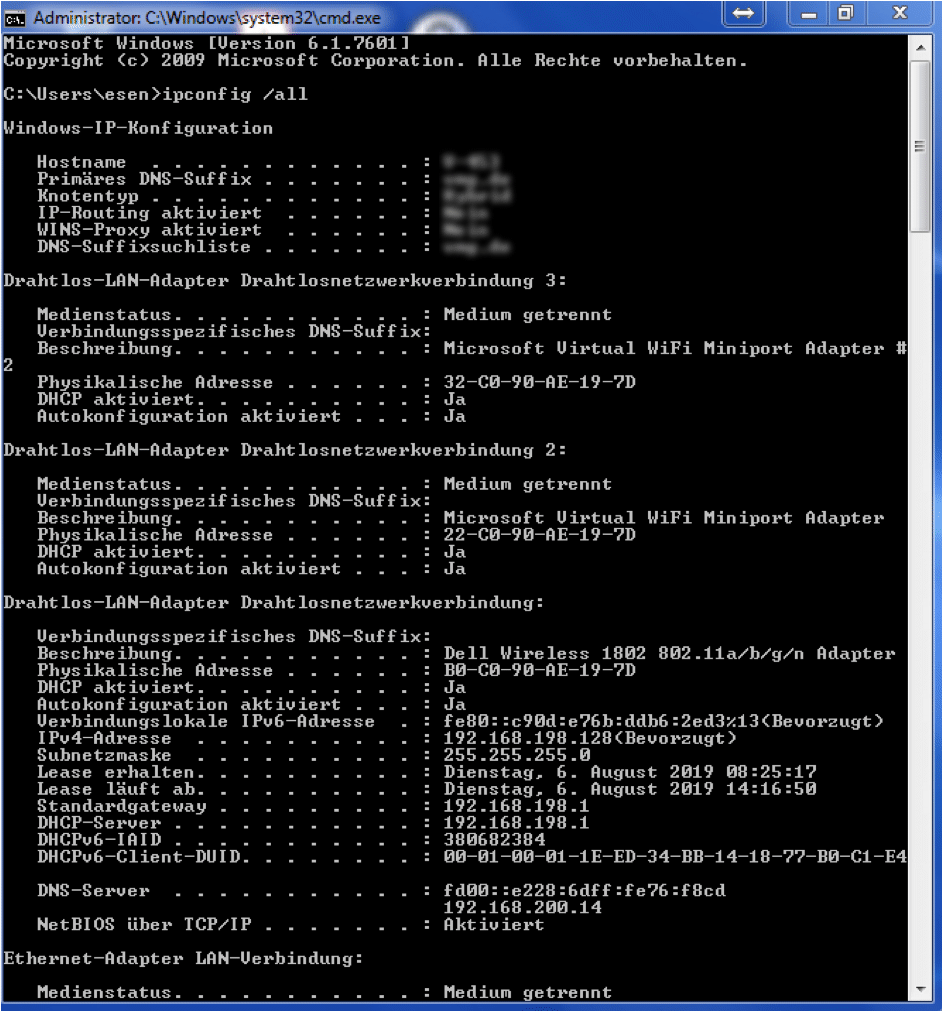
Abbildung 4 - Ausgabe vom Befehl "ipconfig /all" im Terminal
Suchen Sie anschließend nach dem Begriff „Drahtlos-LAN-Adapter Drahtlosnetzwerkverbindung“. info: Achten Sie darauf, dass Sie nicht den falschen Adapter auswählen, insbesondere wenn unter der Beschreibung „Microsoft Virtual WiFi Miniport Adapter“ steht, dann können Sie davon ausgehen, dass es sich hierbei um genau den falschen handelt.
Man kann es auch relativ einfach erkennen, ob es sich hierbei um den korrekten Netzwerk-Adapter handelt, wenn in der Beschreibung ein Name wie „Dell Wireless“ steht, oder ein anderer PC- Hersteller, jedoch nicht „Microsoft Virtual Adapter“. Bei den Begriffen mit „Virtual“ können Sie davon ausgehen, dass es sich hierbei um einen virtuellen Adapter handelt, welches eine andere Funktion hat. Das es den Beitrag sprengen würde, haben wir hierfür einen separaten Artikel geschrieben, welches Sie hier finden.
Wie kann ich unter Windows 10 die Mac-Adresse auslesen?
Schritt 1:
Gehen Sie auf „Start“  und tippen Sie „cmd“ ein gehen Sie auf
und tippen Sie „cmd“ ein gehen Sie auf ![]() . Anschließend befolgen Sie Schritt 2 ab Abbildung 3 (siehe oben).
. Anschließend befolgen Sie Schritt 2 ab Abbildung 3 (siehe oben).
![]()
Abbildung 5 - Terminal in Windows 10 aufrufen
|
App Anfrage 0176 75 19 18 18
Kostenfreie Erstberatung |

