„ Sehr gute Beratung bei der Konzeption unserer App. " Ayse
„ Sehr gute Beratung bei der Konzeption unserer App. " Ayse




In unseren News finden Sie Fachartikel über allgemeine Themen Rund um IT
Eine MAC-Adresse (Media-Access-Controll) ist eine eindeutige und in der Regel nicht veränderbare ID. Jedes Gerät mit einem Netzwerkadapter auf der Welt hat eine MAC-Adresse. Diese Adresse kann meistens auf Aufklebern auf den Geräten ausgelesen werden oder über die Kommandozeile. Je nachdem um welches Endgerät es sich hierbei handelt, sind die Wege unterschiedlich. Im Folgenden zeigen wir Ihnen die gängigsten Geräte auf denen ihr die eigene MAC-Adresse auslesen könnt.
Schritt 1: unter Windows 7:
Gehen Sie auf Start 
Abbildung 1 - Start Button von Windows 7
Abbildung 2 - Suchleiste
Schritt 2:
Geben Sie in die aufpoppende Suchleiste „CMD“ ein und klicken Sie auf ![]() . Anschließend öffnet sich das Terminal wie in Abbildung 3.
. Anschließend öffnet sich das Terminal wie in Abbildung 3.
Abbildung 3 - Terminal (CMD) von Windows
Geben Sie den Befehl „ipconfig /all“ ein
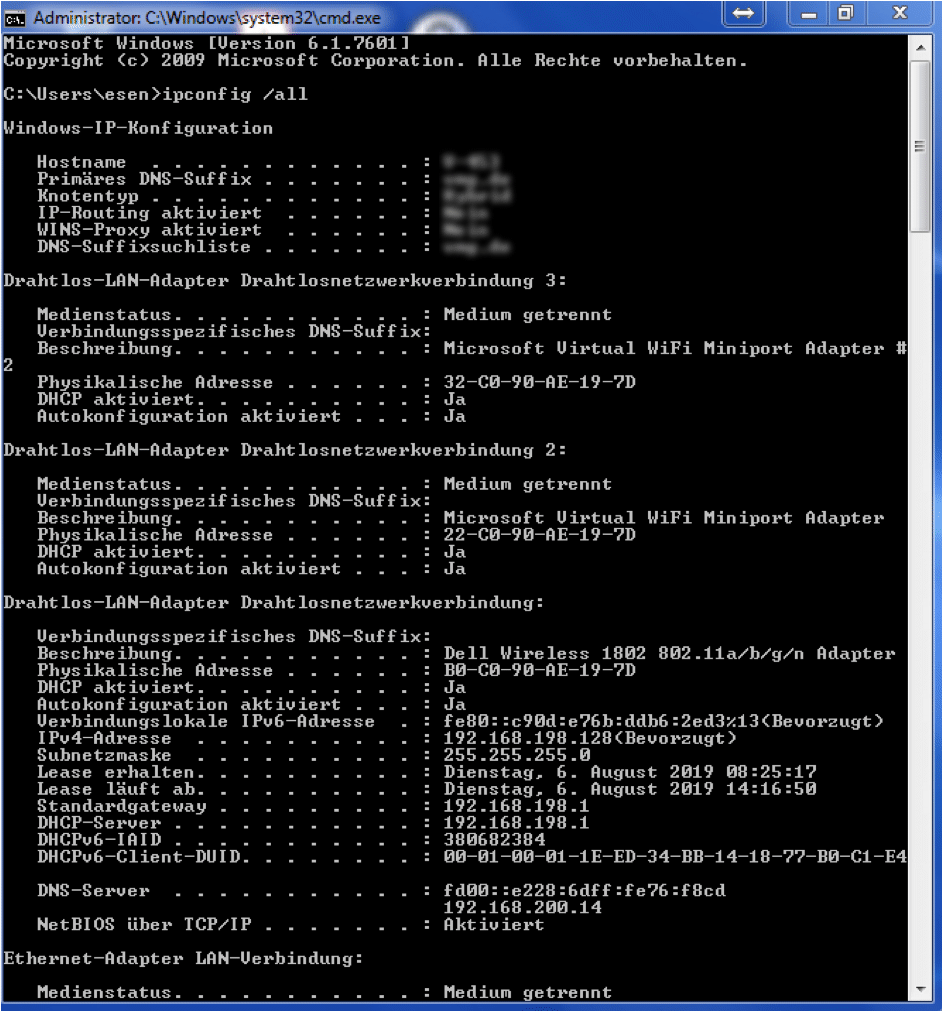
Abbildung 4 - Ausgabe vom Befehl "ipconfig /all" im Terminal
Suchen Sie anschließend nach dem Begriff „Drahtlos-LAN-Adapter Drahtlosnetzwerkverbindung“. info: Achten Sie darauf, dass Sie nicht den falschen Adapter auswählen, insbesondere wenn unter der Beschreibung „Microsoft Virtual WiFi Miniport Adapter“ steht, dann können Sie davon ausgehen, dass es sich hierbei um genau den falschen handelt.
Man kann es auch relativ einfach erkennen, ob es sich hierbei um den korrekten Netzwerk-Adapter handelt, wenn in der Beschreibung ein Name wie „Dell Wireless“ steht, oder ein anderer PC- Hersteller, jedoch nicht „Microsoft Virtual Adapter“. Bei den Begriffen mit „Virtual“ können Sie davon ausgehen, dass es sich hierbei um einen virtuellen Adapter handelt, welches eine andere Funktion hat. Das es den Beitrag sprengen würde, haben wir hierfür einen separaten Artikel geschrieben, welches Sie hier finden.
Wie kann ich unter Windows 10 die Mac-Adresse auslesen?
Schritt 1:
Gehen Sie auf „Start“  und tippen Sie „cmd“ ein gehen Sie auf
und tippen Sie „cmd“ ein gehen Sie auf ![]() . Anschließend befolgen Sie Schritt 2 ab Abbildung 3 (siehe oben).
. Anschließend befolgen Sie Schritt 2 ab Abbildung 3 (siehe oben).
![]()
Abbildung 5 - Terminal in Windows 10 aufrufen

Jeder nutzt heutzutage ein Modem, nur die wenigsten von Ihnen wissen es vermutlich. Es kann auch daran liegen, dass das Wort heutzutage eher als Synonym für einen Router verwendet wird, was prinzipiell jedoch falsch ist. Ein Modem und ein Router machen nämlich zwei unterschiedliche Dinge, welche ich ihnen in diesem kurzen Beitrag erklären werde.
Vielleicht kennen Sie es von früher, dass Sie über Windows eine DFÜ Verbindung herstellen mussten. In den Zeiten von Windows XP, wurde in den „Einstellungen -> Arbeitsplatz / DFÜ-Netzwerk -> Neue Verbindung“ eine PPPOE Verbindung aufgebaut. Oft hat zu dem Zeitpunkt auch ihr Endgerät merkwürdige Geräusche gemacht. Dies war zu der damaligen Zeit, der klassische Ton, wenn man sich ins Internet eingewählt hatte. Früher war es wesentlich teurer eine Internetverbindung Zuhause zu haben. Oder vielleicht kennen Sie auch noch die kostenfreien AOL-CD’s womit man für einen kurzen Testzeitraum im Internet surfen konnte. Falls man eine Leitung hatte, dann wurde meistens auch pro Minute abgerechnet. Da mehr und mehr Nutzer von Dialern bedroht wurden, wurden von den Internet-Service-Anbietern, dann auch die letzten alten Verträge in Flat-DSL-Verträge umgewandelt. Kurz zu Dialern: Hierbei handelt es sich kleine Schadprogramme die teure 0190 Nummern gewählt haben, um die Kunden über das Ohr zu hauen. Zum Monatsende bekam man dann eine teure Rechnung für Rufnummern, die man nie gewählt hatte. Zu dieser Zeit war es auch sinnvoll, sich nur einzuwählen, wenn man das Internet benötigt hatte. Heutzutage ist eine permanente Internetverbindung von allen möglichen Endgeräten schon allgegenwärtig.
Aber jetzt mal wieder zurück von der Nostalgie zu unserem eigentlichen Thema. Um es kurz zu halten: Ein Modem kann nur eine Verbindung zur Verteilstelle ihres Internentanbieters (ISP) aufbauen. Hierzu sind ein Benutzername und ein Passwort notwendig. Bei Telekom-Verträgen ist dann meistens auch noch eine Mitbenutzernnummer zu finden.
Nachdem Sie eine mit ihrem Computer eine Verbindung zu ihrem Modem aufgebaut haben, dann sind sie auch schon im Internet eingewählt. Das Problem hierbei ist, dass sie nur einen Computer an ihrem Modem anschließen können. Genau hier kommt dann der Router ins Spiel. Der Router ist mit seinem integrierten Switch die Sammelstelle für alle Clients (Computer) und überträgt (routet) diese Anfragen an den Modem, welches wiederum ihren gesamten Datentraffic an die Zwischenstelle ihres Internet Service Providers schickt.

Bei Ihrer Arbeit mit Computern werden Ihnen schon häufig verschiedene Dateiformate untergekommen sein. Bei der Vielzahl an verschiedensten Dateitypen und -varianten geht schnell einmal der Überblick verloren. Mit diesem Artikel beginnen wir eine Artikelreihe, die sich verschiedenen Dateitypen widmen wird.
Zuallererst sollte die Frage geklärt werden, warum es überhaupt eine so große Bandbreite an verschiedenen Textdokumenten gibt. Zum einen liegt das daran, dass verschiedene Anwendungsbereiche verschiedene Voraussetzungen an die verwendeten Dateien stellen.
Beispielsweise ist es in der Maschinensprache völlig irrelevant, wie Informationen optisch formatiert sind, da Maschinen nur 0er und 1er verstehen – egal, wie groß, in welcher Schrift oder ob fett gedruckt. Diese Nicht-Formatierung nennt man auch plain text (engl. f. Klartext). Durch das Weglassen unnötiger Formatierungsinformationen wird hier sowohl der benötigte Speicherplatz verringert als auch die Verarbeitungsgeschwindigkeit erhöht.
Andererseits wollen Sie bestimmt keine Geburtstagseinladung in Klartext ohne jegliche Formatierung verschicken, oder? Neben dem reinen Klartext benötigen wir also auch andere Dateiformate, die den jeweiligen Anforderungen Rechnung tragen.
Ein weiterer Grund für die Vielzahl an Dateiendungen ist, dass verschiedene Hersteller gerne ihr eigenes Süppchen kochen und ihr ganz eigenes Dateiformat verwenden möchten. Manchmal hat dies seine Berechtigung, wenn beispielsweise das Textprogramm viele Features hat, die die meisten anderen Textverarbeitungsprogramme eben nicht aufweisen. Als Beispiel kann hier das .pap Format von Papyrus Autor genannt werden, das eine Vielzahl an verschiedenen Informationen und Daten abspeichert und für Vielschreiber wie Journalisten oder Schriftsteller gedacht ist. Andererseits gibt es auch das .pages Format, das im Prinzip nichts anderes ist als die Apple-Variante von .doc.
Weiterhin kann die Weiterentwicklung eines Formates dafür verantwortlich sein, dass sich mehrere Varianten eines Dateityps etablieren, so zum Beispiel bei .doc und .docx von Microsoft geschehen.
Kommen wir zu den am weitesten verbreiteten und von der Microsoft Corporation entwickelten Dateiformate für Textdokumente. Bereits in den 1980er Jahren arbeite Microsoft an eigenen Dateiformaten, die sogar noch bis heute Verwendung finden.
.rtf: Rich Text Format
Das bereits 1987 eingeführte Rich Text Format von Microsoft dient in erster Linie als Austauschformat zwischen verschiedenen Textverarbeitungsformaten. Da es im Gegensatz zu reinem plain text eine breite Palette an Textformatierungsmerkmalen enthält und nicht an eine bestimmte Software gebunden ist, eignet es sich hervorragend für den Austausch von Dateien über verschiedene Betriebssysteme hinweg.
Beinahe alle Textverarbeitungsprogramme können dieses Dateiformat verarbeiten, allerdings wird keine Layouttreue gewährleistet, da insbesondere Vorlagen und Bilder, Textrahmen oder andere Objekte das Layout beim Öffnen mit anderen Programmen beeinträchtigen können. Die verwendeten Schriftarten müssen allerdings auf dem Betriebssystem installiert sein, damit sie verwendet werden können, da diese nicht in die Textdatei eingebettet werden.
Dieses Dateiformat war eine der wenigen Möglichkeiten, Texte ohne großen Aufwand zwischen Windows und DOS auszutauschen. Weiterhin ist es das Standard-Dateiformat des Textverarbeitungsprogramms WordPad.
Mittlerweile hat dieses Dateiformat jedoch zunehmend an Bedeutung verloren.
.doc: Das Dokument
Dieses Dateiformat ist das wohl bekannteste Format, das es überhaupt gibt. Es wurde mit Microsoft Word 1983 offiziell eingeführt und erst 20 Jahre später mit der Version von 2007 durch das Folgeformat .docx abgelöst.
Allerdings blieb das Format nicht für zwei Jahrzehnte vollkommen unverändert. Natürlich wurde es immer wieder um Funktionen erweitert, doch verzichtete Microsoft darauf, mit einer neuen Variante auch eine neue Dateiendung einzuführen. So gibt es beispielsweise zwischen Office 1995 und Office 1997 einen Einschnitt in der Kompatibilität. Zwar werden die Dateien vor und nach diesem Einschnitt als .doc Dateien abgespeichert, sie sind allerdings so unterschiedlich, dass sie eigentlich zwei verschiedene Formate darstellen und dementsprechend auch nicht kompatibel zueinander sind.
Das .doc Format beherrscht neben reiner Textformatierung auch Tabellen, Bilder und andere Objekte.
.docx: Der neue offene Standard
Das .docx Dateiformat gehört zu einer Reihe von von Microsoft entwickelten Formaten, die unter Office Open XML zusammengefasst werden. .docx-Dateien werden seit 2007 standardmäßig von Microsoft Word verwendet. Die beiden anderen Formate sind .xlxs und .pptx und sind neuen Standards für Microsoft Excel und PowerPoint.
Das Format basiert auf XML (Extensible Markup Language) und ist frei verfügbar. Durch die extrem weite Verbreitung von Microsoft Word (über eine Milliarde Nutzer) kann das .docx Format mittlerweile als de facto Standard angesehen werden. Da es von allen gängigen Textverarbeitungsprogrammen verarbeitet werden kann ist es unwahrscheinlich, dass sich daran in absehbarer Zukunft etwas ändern wird.
Entwickelt wurde dieser neue Standard, da das ältere .doc Format nicht offen verfügbar war und der Ruf nach einem offenen Dateiformat vor allem von Regierungen in den USA und in der EU immer lauter wurden.
Ähnlich wie das .docx Format von Microsoft basiert .odt (Open Document Writer) auf XML. Allerding ist .odt (genauso wie alle anderen Open Document Formate) vollständig OpenSource.
Microsoft erklärt auf seiner Internetseite, dass einige Features von Word nicht vom .odt Format unterstützt werden. Generell kann man sagen, dass das .odt Format eher für die Allgemeinheit ausgelegt ist, da es schlichtweg nichtkommerziell ist, wohingegen Microsoft stets ein wirtschaftliches Interesse mit seinen, wenn auch offenen, Standardformaten verfolgt.
Daraus resultieren Eigenheiten des .odt Formats, die für den Nutzer von Vorteil sind. Beispielsweise können mit dem OpenSource-Format ausfüllbare Formulare erstellt und direkt als PDF-Datei exportiert werden. Unter Word funktioniert das auch, allerdings ist das PDF-Formular dann nicht mehr ausfüllbar. Microsoft setzt hier auf die hauseigenen Vorlagen, die jedoch weitaus umständlicher zu erstellen sind als ihre Pendants mit .odt. Das odt. Format liefert damit eine weitaus simplere Variante zum Erstellen solcher Formulare.
Neben den oben genauer vorgestellten Dateiformaten gibt es noch eine ganze Reihe weiterer Formate, die hier kurz vorgestellt werden sollen.
Ein wichtiger Hinweis für die Nutzung von Textdateien, die Makros beinhalten: Diese Dateien können enorme Schäden am PC des Nutzers verursachen, da die Makros beim Aufrufen der Dateien Skripte ausführen können, die einem Computervirus oder Trojaner gleichkommen. Dateien mit enthaltenen Skripten erkennt man unter anderem an den Dateiendungen .docm oder .dotm.
Beim Umgang mit solchen Dateien sollte darauf geachtet werden, dass niemals makrobehaftete Dateien aus unbekannten oder nicht vertrauenswürdigen Quellen geöffnet werden sollten. Um sicher zu gehen, dass nicht aus Versehen solche Dateien geöffnet werden können, empfiehlt es sich, die Makrofunktionen beispielsweise in Microsoft Word komplett zu deaktivieren. Nähere Informationen zu diesem Thema finden Sie in unserem Artikel darüber.
Sollten Sie dennoch Probleme mit solchen Dateien haben, helfen wir Ihnen sehr gerne weiter. Unsere qualifizierten IT-Spezialisten aus München kümmern sich um jede Art von Malware oder von Makros verursachten Schäden auf Ihrem Computer.
Kontaktieren Sie uns einfach
Wir freuen uns auf Sie!

Mit diesem Artikel wollen wir eine kleine Reihe starten, die sich mit verschiedenen Dateiendungen beschäftigt und ein wenig Aufschluss darüber gibt, was die gängigsten Dateitypen ausmacht und was sie voneinander unterscheidet. Doch zuerst klären wir, was Dateiendungen überhaupt sind und wozu sie überhaupt dienen.
Genannt werden sie auch Dateierweiterung oder Dateiendung und sind der letzte Teil des Dateinamens. Gewöhnlich wird diese Endung vom Rest des Namens mit einem Punkt abgetrennt, wobei der Punkt allerdings nicht Teil der Erweiterung ist.
Die Dateiendungen dienen dazu, das Format der Datei erkenntlich zu machen. Da sie aber nicht normiert sind, ist es prinzipiell auch möglich, dass eine Endung für verschiedene Dateitypen verwendet wird, was allerdings im Allgemeinen vermieden wird, um offensichtliche Missverständnisse und Probleme zu verhindern.
Es ist möglich, die Dateiendung durch einfaches Umbenennen zu verändern, was dazu führen kann, dass manche Betriebssysteme (allen voran Windows) dann diesen neuen Dateityp annehmen, letztlich jedoch beim Öffnen daran scheitern, dass die Datenstruktur eine völlig andere ist. Um das versehentliche Verändern der Dateiendung zu verhindern, werden die Dateiendungen oft ausgeblendet (unter Windows ist dies beispielsweise über die Einstellungen des Explorers möglich).
Generell nutzt die Dateiendung in erster Linie dem Nutzer, um zu erkennen, um was für eine Art Datei es sich handelt. Dadurch kann beispielsweise entschieden werden, welches Programm man zum Öffnen dieser Datei benötigt. Es hilft aber auch dabei zu entscheiden, ob eine Datei vertrauenswürdig ist oder nicht. Eine .exe oder .bat Datei aus einer unbekannten Quelle beispielsweise ist potenziell sehr gefährlich, da sie Viren oder andere Schadsoftware enthalten kann.
Für manche Betriebssysteme (zum Beispiel Windows) ist die Dateiendung allerdings wichtig, um zu erkennen, welches Dateiformat vorliegt. Windows verlässt sich nämlich nur auf die Endung der Datei, um ein Programm auszuwählen, mit dem sie geöffnet werden soll. Dabei weist das Betriebssystem jede Dateiendung einem bestimmten Programm zu, mit dem es standardmäßig geöffnet werden soll. Wie bereits erwähnt sind Dateiendungen allerdings nicht normiert und können ohne Probleme vom User abgeändert werden. Deshalb kann es passieren, dass Windows dann nicht weiß, wie es die betreffende Datei öffnen soll.
Andere Systeme hingegen (wie beispielsweise macOS oder Unix) verlassen sich nicht nur auf die Dateiendung, sondern verwenden andere beziehungsweise zusätzliche Mechanismen für das Erkennen des Dateityps. Beispielsweise können die Versionsnummer oder die Plattformangabe in der Datei zu Rate gezogen werden.
Weiterhin wird auch eine Mischung aus diesen beiden Varianten angewandt. So verlässt sich KDE (K Desktop Environment), die grafische Oberfläche vieler Linux-Derivate, zunächst auf die Dateiendung. Wenn daraus keine eindeutige Klassifizierung des Dateityps erfolgen kann, weil die Endung fehlt oder dem System unbekannt ist, kann KDE auch den Inhalt der Datei verwenden, um auf eine Lösung des Problems zu kommen.
Durch das standardmäßige Ausblenden der Dateiendungen ergibt sich nicht nur der Vorteil, dass man sie nicht mehr aus Versehen ändern kann und damit Schaden anrichten könnten. Daraus resultiert auch, dass die tatsächliche Endung der Datei verschleiert bleibt, was in manchen Situationen (wenn zum Beispiel die Dateiendung relevant für den Arbeitsprozess ist) unvorteilhaft sein kann, sondern sie birgt auch ein großes Sicherheitsrisiko.
So kann beispielsweise vor die eigentliche Endung der Datei eine harmlose Dateiendung eingefügt werden:
Bild.jpeg.exe
Dadurch, dass unter Windows die Dateiendungen standardmäßig nicht angezeigt wird, kann hieraus ein enormes Sicherheitsrisiko entstehen, da der User vermeintlich denkt, dies sei eine normale Bilddatei im .jpeg-Format. In Wirklichkeit ist es eine Executable (also ausführbare Datei) und kann beispielsweise einen Virus oder Trojaner enthalten.
Es ist also zu empfehlen, die Anzeige der Dateiendungen zu aktivieren, auch wenn man diese aus Versehen verändern könnte – das lässt sich rückgängig machen, den ausgeführten Virus bekommen sie hingegen nicht so einfach wieder von Ihrem Rechner runter.
Die Dateiendungen sind in erster Linie eine Informationsquelle für den User und für das Betriebssystem, damit dieses mit der Datei umgehen kann. Allerdings bergen Dateiendungen mitunter Gefahren.
In den weiteren Artikeln dieser Reihe werden wir uns mit den verschiedensten Dateiendungen auseinandersetzen und zeigen was sie unterscheidet.
Haben auch Sie ein Problem mit einer Dateiendung? Können Sie eine Datei nicht öffnen? Oder haben Sie sich gar Malware eingefangen, die beseitigt werden muss? Dann helfen wir Ihnen gerne dabei! Unsere qualifizierten Techniker kümmern sich gerne um Ihr Computer-Problem!
Kontaktieren Sie uns noch heute!
Wir freuen uns auf Sie!

Im zweiten Teil unseres Artikels über DNS over HTTPS behandeln wir die Schwachstellen des DNS, wie es ausgenutzt werden kann und wie neue Technologien diese Sicherheitslücken schließen sollen.
Im Normalfall teilt der Resolver dem DNS-Server mit, nach welcher Domain man sucht. Außerdem beinhaltet die Anfrage zumindest einen Teil der eigenen IP-Adresse. Da man sich die fehlenden Teile durch anderweitige Informationen erschließen könnte, hätten Angreifer sämtliche Möglichkeiten, Ihren Rechner ins Visier zunehmen. Es gibt zwei Möglichkeiten, wie Hacker dies nun ausnützen könnten, um sich Ihnen gegenüber einen Vorteil zu verschaffen, das Tracking und das Spoofing.
Es ist also nicht sonderlich schwer Ihre IP-Adresse während einer Anfrage beim DNS-Server auszulesen. Vielleicht denken Sie sich jetzt, dass das ja an sich kein Problem darstellt, Sie haben schließlich nichts zu verbergen? Das mag sein, allerdings wollen Sie sicherlich auch nicht, dass Ihre Daten beziehungsweise Ihr Surfverhalten verkauft werden, oder?
Mit Ihrer IP-Adresse lässt sich mit der Zeit nämlich leicht ein Profil von Ihnen erstellen – was sie suchen, einkaufen, welche Seiten sie häufig besuchen, welche Interessen sie haben. Dadurch lässt sich wunderbar personalisierte Werbung für sie schalten, damit sie noch mehr einkaufen von dem, was sie ohnehin bereits besitzen.
Allerdings hört das nicht bei Werbung auf. Ihre Daten sind äußerst wertvoll für viele Firmen, die unheimlichen Profit daraus schlagen – Google ist nicht umsonst durch den Verkauf solcher Daten milliardenschwer geworden.
Und selbst wenn Sie Ihrem Resolver, den Sie für Ihr privates Netzwerk eingerichtet haben, vertrauen – sobald sie mobil unterwegs sind, ein fremdes WLAN verwenden oder sich in einem Hotel einloggen, verwenden Sie möglicherweise einen anderen Resolver, der dann eben nicht mehr vertrauenswürdig ist. Und wer weiß schon, wie dieser Resolver mit denen von Ihnen gesammelten Daten umgeht?
Beim Spoofing klinkt sich jemand in Ihre Verbindung ein und verändert die Antwort, die vom DNS Server an Ihren Browser zurückgesendet wird. Anstatt Ihnen also die IP-Adresse der Seite, die Sie besuchen wollen, zu geben, wird Ihnen eine falsche Adresse zugesteckt. Auf diese Weise kann eine Seite Sie davon abhalten eine bestimmte Seite zu besuchen.
Warum sollte eine Seite tun? Nehmen wir folgendes Beispiel: Sie stehen in einem Laden und wollen die Preise im Regal mit denen im Internet bei einem anderen Anbieter vergleichen. Sollten Sie nun im WLAN-Netzwerk des Ladens sein, in dem Sie gerade stehen, verwenden Sie auch den Resolver, der in diesem Netzwerk eingerichtet ist. Und dem Geschäft wäre sicherlich daran gelegen, dass sie keine günstigeren Preise finden, als die, die sie im Laden vor sich haben, oder?
Und schon haben Sie ein Motiv dafür, eine andere, verfälschte Internetseite anzeigen zu lassen oder die gesuchten Vergleichsportale einfach vollständig zu blockieren.
Netzwerke kommen im Normalfall ohne Probleme mit den oben genannten Praktiken davon, da die wenigsten Nutzer überhaupt davon wissen, geschweige denn sich damit auskennen und Gegenmaßnahmen ergreifen könnten. Und vielen wäre es wohl auch ziemlich egal, selbst wenn sie davon wüssten. Doch selbst für User, die sich mit der Materie auskennen, ist es schwierig, dafür zu sorgen, dass mit ihren Daten kein Schindluder getrieben wird.
Nun gibt es neben Browsern, die zu Firmen mit wirtschaftlichen Interessen gehören, auch Initiativen, die OpenSource und non-profit arbeiten. Die Mozilla Foundation beispielsweise arbeitet an Lösungen, die diese Sicherheitslücken schließen.
Der Mozilla Firefox nutzt nun also standardmäßig den sogenannten Trusted Recursive Resolver (TRR), der in hohem Maße darauf ausgelegt ist, keine verwertbaren personenbezogenen Daten der Nutzer weiterzugeben oder zu speichern. So werden sämtliche für die Suchanfragen verwendeten Informationen innerhalb von 24 Stunden wieder gelöscht. Der OpenSource-Browser kann damit den vom Netzwerk vorgegebenen Resolver ignorieren und eine sichere Variante verwenden.
Neben dem Verwenden eines auf Privatsphäre getrimmten Resolvers sorgt die Verschlüsselung der Suchanfragen eine große Rolle. So wird mittlerweile standardmäßig (und von allen aktuellen Browsern) das HTTPS-Protokoll angewandt.
Weiterhin sendet der TRR von Firefox nicht die gesamte angefragte Domain, sondern immer nur den Teil der Adresse, der für den Server, der gerade kontaktiert wird, relevant ist. Außerdem wird die Anfrage von dem von Firefox genutzten Dienst Cloudflare nicht weitergeleitet, sondern die Anfrage wird von einer dem Dienst eigenen IP-Adresse gesendet.
So wird nur ein Minimum an Informationen versandt, sodass zumindest der Aufwand, Rückschlüsse auf die Zieladresse oder die IP-Adresse zu erhalten, bei weitem größer wird.
Auf die oben genannte Weise wird also die Zahl derjenigen, die Ihre Daten abgreifen können, um ein Vielfaches reduziert. Allerdings sind Ihre Verbindungen damit noch nicht vollständig sicher.
Nachdem Sie über den DNS-Server herausgefunden haben, wo Sie das Ziel Ihrer Suche finden können, müssen Sie sich erst noch mit dem jeweiligen Server verbinden. Um dies zu tun, schickt der Browser eine Anfrage an diesen Server – und diese Anfrage ist nicht verschlüsselt. Hier kann sich also sehr wohl jemand einklinken und mithorchen, welche Seiten Sie besuchen.
Sobald Sie allerdings mit dem jeweiligen Server verbunden sind, ist alles verschlüsselt. Praktischerweise gilt das auch für alle Seiten, die auf diesem Server gehostet werden. Schlagen Sie beispielsweise einen weiteren Wikipediaartikel nach, der auf demselben Server gespeichert ist, so wird keine vollständige Anfrage an den Server geschickt, sondern die bestehende (verschlüsselte) Verbindung wird weiterhin verwendet.
Da das DNS eines der ältesten Grundbausteine des Internets ist und an dessen Struktur sich nicht viel verändert hat was die Privatsphäre oder Datensicherheit verbessert, ist es an der Zeit, dies in Angriff zu nehmen. Gemeinnützige Initiativen wie Mozilla unterstützen diese Weiterentwicklung und bringen sie bewusst voran.
Wer an Mozillas Studie zur Weiterentwicklung des oben beschriebenen TRR mitwirken möchte, kann sich hierfür die in Entwicklung befindende Firefox Nightly auf der Mozilla-Homepage herunterladen.

Wie würden Sie einem Kollegen erklären, was Ihr Browser im Hintergrund anstellt, wenn Sie ihn anweisen, eine Internetseite aufzurufen? Überfragt? Dann hilft Ihnen der folgende Artikel weiter. Hier erklären wir, was DNS und HTTPS sind und wie sie zusammenspielen.
Mit der zunehmenden Digitalisierung und der Omnipräsenz des Internets im alltäglichen Leben steigt auch das Verlangen nach der Gewährleistung von Privatsphäre und Datenschutz. Durch neue Datenschutzgesetze (zum Beispiel die DSGVO) soll diesem Verlangen Sorge getragen werden. Aber auch Softwareunternehmen und Organisationen arbeiten zunehmend an Sicherheitslösungen – nicht nur aus Gründen des Datenschutzes, sondern auch aus eigenem und wirtschaftlichem Interesse natürlich. HTTP steht dabei für Hypertext Transfer Protocol.
Kommen wir auf unsere Ausgangsfrage zurück: Was passiert, wenn Sie eine Internetseite aufrufen? Eine einfache Antwort wäre, dass der Browser erst eine Anfrage an den Server verschickt, dass er die Seite gerne anzeigen würde und der Server dann eine Antwort verschickt, in der die Datei steckt. Das nennt man dann HTTP und dürfte Ihnen bekannt vorkommen – etwas ähnliches steht in der Adresszeile Ihres Browsers ganz am Anfang.
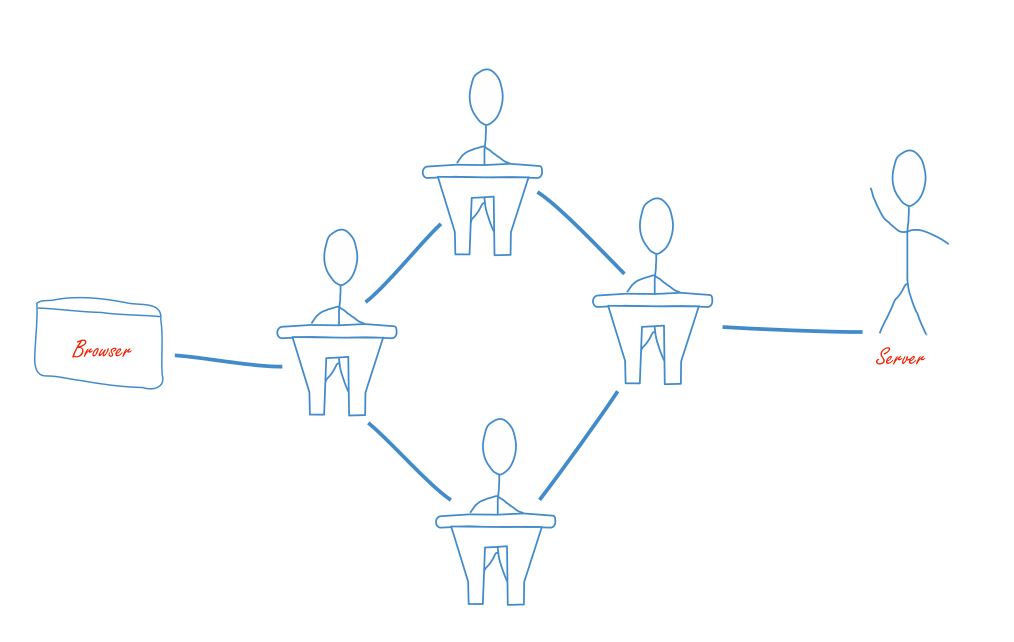
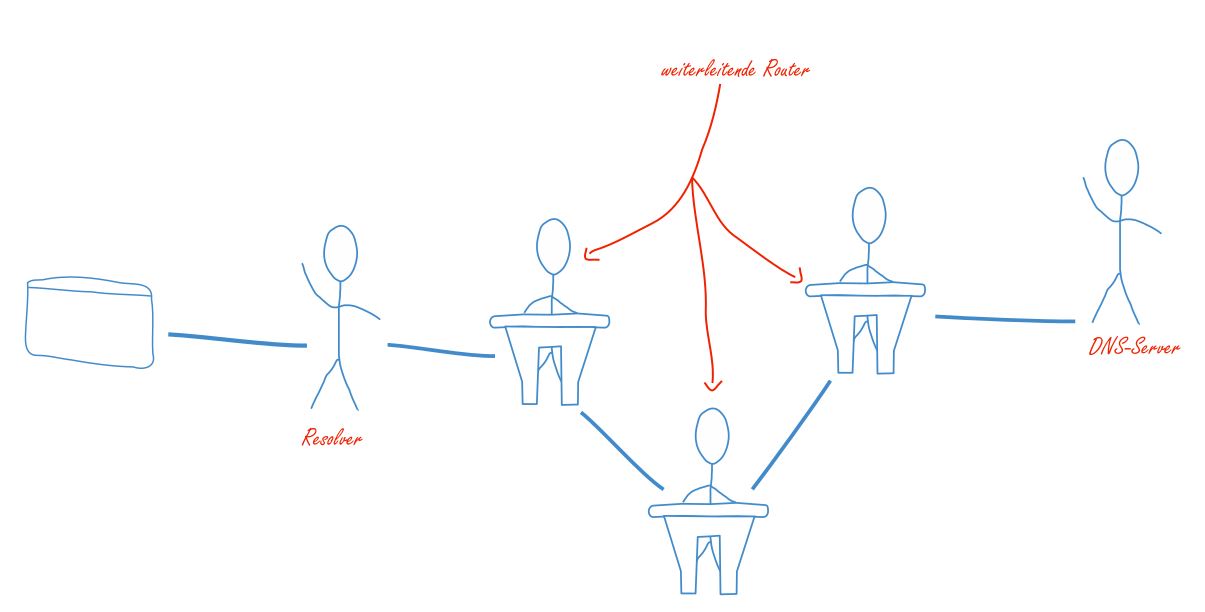
Das Problem bei der Sache ist: So einfach funktioniert das Internet dann doch nicht. Denn normalerweise steht der Server, den Ihr Browser kontaktiert nicht gleich bei Ihnen ums Eck, sondern gerne auch mal auf einem völlig anderen Kontinent. Und dorthin gibt es von Ihrem PC aus auch keine direkte Kabelverbindung. Also müssen hierfür Mittelsmänner herhalten, die erst die Anfrage an den Server weitergeben und das gleiche dann auch mit der Antwort machen.
Diese Prozedur ist gut mit einem Klassenzimmer vergleichbar. Ein Schüler schreibt einen Brief und den Namen des Adressaten außen drauf, um ihn dann über mehrere Stationen an einen weiter entfernten Mitschüler zu schicken. Das Problem dabei ist, dass vielleicht nicht jeder der Mitschüler, durch deren Hände der Brief wandert, auch vertrauenswürdig sind und nicht neugierig den Inhalt des Briefes lesen.
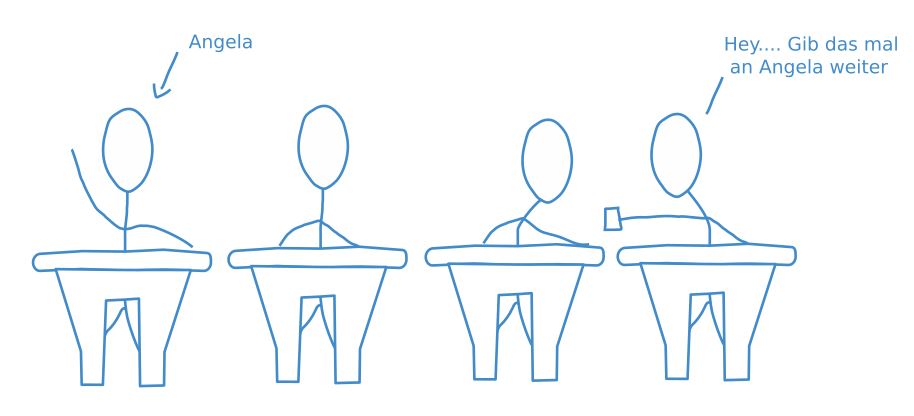
Um diesen neugierigen Mitschülern entgegen zu wirken, wurde HTTP weiterentwickelt zu HTTPS – und das ist das, was tatsächlich in der Adresszeile Ihres Browsers steht. Das angehängte S steht für secure, also sicher. Man kann sich diese Weiterentwicklung als Brief mit Vorhängeschloss vorstellen, zu dem nur der Sender und der Empfänger den Schlüssel haben, die einzelnen Mittelsmänner (oder Schüler) aber eben nicht.
Dieses virtuelle Vorhängeschloss behebt schon einige Sicherheitslücken. Absolut sicher ist es aber auch nicht. Zum einen muss der Sender als ersten Schritt den Server kontaktieren, um eine Verschlüsselung aufbauen zu können. Diese erste Kontaktaufnahme ist aber logischerweise noch nicht verschlüsselt, da der Server sonst nichts damit anfangen könnte.
Die zweite Lücke, an der die Daten noch immer ungeschützt sind, besteht am DNS.
Die DNS hat in diesem Fall nichts mit Genetik zu tun, sondern steht für Domain Name System. Wie in unserem Vergleich mit dem Klassenzimmer muss auf der Anfrage des Nutzers quasi der Name des Empfängers stehen. Da der Server aber mit dem Klarnamen der Homepage nicht wirklich etwas anfangen kann, muss dieser so gestaltet sein, dass der Server versteht, was zu tun ist. Dies wird über das DNS erreicht.
Im Prinzip wird über das DNS jeder Internetseite nur eine IP-Adresse zugeordnet, mit der sie eindeutig zu erreichen ist. Damit der Browser weiß, wie er das tun muss, müsste er über eine sehr lange Liste verfügen, in der alle verfügbaren Webseiten eingetragen sind, ähnlich einem Telefonbuch. Allerdings hätte man damit das Problem, dass bei der enormen Menge an neu angelegten Webseiten diese Liste gar nicht schnell genug aktualisiert werden könnte. Also unterteilt man sie einfach in eine Reihe weitere Listen.
Es entsteht also quasi eine Datenbank mit vielen Unterlisten, die separat verwaltet und aktualisiert werden können. Schauen wir uns beispielsweise folgende Internetadresse an:
de.wikipedia.org
Die Punkte in der Adresse separieren die einzelnen Teillisten voneinander. Dabei geht der Browser (beziehungsweise der sogenannte Resolver) von hinten nach vorne vor. Als erstes wird also ein Server (der Root DNS Server) kontaktiert, der dann einen Server mit der Liste für die top-level Domains zurückgibt. In unserem Fall bräuchten wir einen Server, der mehr über .org Domains weiß.
Auf diesem Server finden wir dann wiederum alle Informationen über die second level domains, die unter .org zu finden sind. Für uns wäre das also der Namensserver für Wikipedia. Dieser Server kann uns dann weiterverbinden auf den zuständigen Server für die subdomains von Wikipedia. Hier bekommen wir nun also die Information, unter welche IP-Adresse die HTML-Datei der deutschen Wikipedia-Seite zu finden ist. Diese Adresse schickt der Resolver dann zurück an Ihren Browser.
Der Resolver ist allerdings nicht immer derselbe. Es gibt zwei Möglichkeiten, wie entschieden wird, welcher Resolver verwendet werden soll. Entweder der Benutzer stell ganz konkret einen Resolver ein, sodass sein Computer immer diesen einen verwendet oder er belässt die Voreinstellungen, sodass der Resolver vom System ausgesucht wird.
Im zweiten Teil unseres Artikels über DNS über HTTPS (DoH) lesen Sie mehr über die Sicherheitsrisiken beim Surfen im Internet, wie diese geschlossen werden können und was Sie als Nutzer aktiv für Ihre Privatsphäre tun können.
Haben Sie Probleme mit dem Internet oder Sicherheitsbedenken beim Surfen? Unsere IT-Spezialisten aus München helfen Ihnen gerne bei allen Ihren PC-Problemen weiter!
Nehmen Sie noch heute mit uns Kontakt auf!
Wir freuen uns auf Ihre Anfrage!

Zur Jahrtausendwende befürchteten viele Menschen, dass es zu einem großflächigen Ausfall der damals vorhandenen IT-Infrastruktur kommen könnte. Ein großer Teil dieser Befürchtungen war reiner Aberglaube, doch gab es den sogenannten Millenium-Bug, der tatsächlich für einige Probleme sorgte, vor allem bei Geräten und Systemen, die in irgendeiner Weise auf eine Datumsanzeige setzten.
Im Jahre 2038 wird es wieder einen solchen Moment geben, in dem durch fehlerhafte Datumsanzeigen schwerwiegende Probleme auftreten könnten, denn am 19. Januar 2038 um 03:14:07 Uhr UTC läuft zwar nicht der Maya-Kalender ab, sondern die sogenannte Unixzeit.
Die sogenannte Unixzeit ist eine Zeitdefinition, die in den 70er Jahren für das Betriebssystem Unix eingeführt wurde. In der aktuell gültigen Definition von 1975 begann die Unixzeit am 1. Januar 1970, 00:00:00 Uhr UTC (UTC = Coordinated Universal Time = koordinierte Weltzeit). Sie zählt dabei die vergangenen Sekunden seit dem Startdatum, wobei Schaltsekunden übersprungen werden.
Die Unixzeit hat insgesamt eine Kapazität von 2.147.483.647 Sekunden, was einer vorzeichenbehaftete 32-Bit-Ganzzahl entspricht (231 – 1). Sobald diese überschritten wird (was im Jahre 2038 der Fall sein wird), springt das Vorzeichen von positiv auf negativ um, was zu einer Zeitangabe weit vor dem 1. Januar 1970 bedeuten würde.
Hier ist das die Krux des Jahr-2038-Promblems zu erkennen. Sämtliche Systeme, die diese 32-Bit-Unixzeit verwenden, werden ab diesem Zeitpunkt ein völlig falsches Datum anzeigen und verarbeiten. In der Softwareentwicklung nennt man dieses Problem auch Zählerüberlauf.
Da Unixsysteme vor allem bei Banken und ihm Versicherungssektor eine weite Verbreitung besitzen, sind diese Wirtschaftszweige natürlich besonders gefährdet, vor allem, da diese Branchen stark auf korrekte Zeitstempel angewiesen sind. Neben diesen Servern und anderen Unixsystemen arbeiten viele eingebettete Systeme (z.B. Router oder elektronische Messgeräte) mit unixartigen Betriebssystemen.
Gravierend könnten die wirtschaftlichen Schäden werden, wenn beispielsweise Transaktionen von Banken nicht getätigt werden, weil sie weiterhin auf den direkten Zeitstempel warten. Der würde allerdings länger auf sich warten lassen, da die Unixzeit fälschlicherweise einen Zeitpunkt im Dezember 1901 angeben würde.
Für die Anwender von unixbasierten Betriebssystemen oder Programmen könnte sich das Jahr-2038-Problem dadurch äußern, dass die Software in eine Endlosschleife gerät und sich dadurch „aufhängt“, da die Programme auf einen gewissen (scheinbar weit in der Zukunft liegenden) Zeitpunkt warten.
Sollte das Problem mit der ablaufenden Unixzeit also nicht rechtzeitig behoben werden, drohen in vielen wirtschaftlichen Bereichen, in den mitunter extrem viel Geld steckt, enorme wirtschaftliche Schäden und Systemtotalausfälle.
Um diesem Problem zu beheben und um eine Wiederholung der Folgen wie beim Millenium-Bug von 2000 zu verhindern, bei dem durch ungenügende Vorbereitung ein ähnlicher Fehler in der Verarbeitung von Jahreszahlen zu wirtschaftlichen Schäden im Bereich von mehreren hundert Milliarden US-Dollar eintraten, werden schon weit im Voraus Vorkehrungen getroffen, um die Schäden zu minimieren oder komplett auszuschließen.
Grundlegend wird die Unixzeit von 32-Bit auf 64-Bit umgestellt, was dazu führen würde, dass die dann neu definierte Unixzeit erst in 292 Milliarden Jahren auslaufen würde. Zum Vergleich: Das Universum ist bisher circa 13,81 Milliarden Jahre alt. Bis das der Fall sein wird, bleibt der Menschheit also noch genug Zeit, um eine technische Lösung für dieses Problem zu finden.
Diese Umstellung ist bereits im Gange und wird sukzessive mit neuen Unixupdates auf die verschiedensten Systeme aufgespielt. Allerdings ist damit das Problem nicht endgültig gelöst oder Schäden abgewandt, da dadurch zwar die Server eine 64-Bit-Unixzeit liefern, die Programme, die noch mit 32-Bit arbeiten diese allerdings nicht verarbeiten können, was erneut zum Jahr-2038-Problem führt. Es müssen also auch sämtliche Programme, die die Unixzeit vernwenden, auf 64-Bit aufgerüstet werden.
Diese Umstellung kann mitunter sehr aufwendig sein, da der komplette Programmcode vieler und komplexer Programme durchforstet und aktualisiert werden muss.
Eine Alternative zur Umstellung auf eine 64-Bit Unixzeit mit Sekundenschritten stellt eine Verkleinerung der Zeitintervalle dar, wie sie so bereits in vielen Entwicklungsumgebungen wie bei JAVA (64-Bit und Millisekunden) eingesetzt werden. Da gerade im Bankensektor eine so hohe zeitliche Genauigkeit von Nöten ist, scheint es sinnvoll, die Unixzeit auch in dieser Hinsicht zu überarbeiten.
Eine weitere Möglichkeit wäre es, den Zeitstempel als Zeichenkette (YYYYMMDDHHMMSS) abzuspeichern, wie es in ISO 8601 bereits vorgesehen ist. Dies würde bis zum Jahreswechsel 9999/10000 ausreichen, um Jahr-Überlauf-Probleme auszuschließen. Allerdings müssten auch hier etliche Programme angepasst werden, da innerhalb eines Programms der Zeitstemepl wieder in ein problematisches Binärformat umgewandelt werden könnten.
Das bereits erwähnte Jahr-2000-Problem (oder Millenium Bug) verursachte zum Jahrtausendwechsel enorme wirtschaftliche Schäden und sorgte sogar für eine Rezession in der Informatikbranche.
Zehn Jahre später, im Jahr 2010 traten einige der für das Jahr 2000 erwarteten Fehler unerwartet auf und überraschte die Wirtschaft. So wurden durch fehlerhafte Datumsformate vor allem bei EC- und Kreditkarten die Jahre 2010 und 2016 vertauscht.
Beim Jahr-2027-Problem werden auf Rechnern der 3000er Serie des Herstellers Hewlett-Packard die Bits für das Datenformat aufgebraucht sein. Da diese Rechner allerdings seit 2015 keinen Support mehr erfahren und bereits mehrere Jahrzehnte alt sind, sind hier keine nennenswerten Schäden zu erwarten.
Im Jahr 2036 werden die Zähler des in Unix-Kreisen weit verbreiteten Zeitsynchronisations-Protokolls NTP (Network Time Protocol) überlaufen, was vor allem für eingebettete Systeme wie Router oder Messgeräte problematisch werden könnte. Diesem Problem wurde allerdings bereits weitestgehend durch moderne Implementierungen entgegengewirkt.
Auch wenn es auf den ersten Blick erschreckend wirken mag, dass die Zeit so vieler Server und Rechner in der Wirtschaft auszulaufen droht, kann an dieser Stelle weitestgehend Entwarnung gegeben werden. Größere Ausfälle oder finanzielle Schäden sind nicht zu erwarten, da bereits Jahrzehnte im Voraus geplant wurde. Lediglich in einzelnen oder veralteten Systemen könnte es zu kleineren Problemen kommen.
Auch wenn bis zum Jahr 2038 noch einige Jahre ins Land gehen werden, treten immer wieder (zum Glück meist weniger schwerwiegende) Probleme mit PCs, Laptops oder anderer Hardware auf. Sollten Sie ein solches Problem haben, wenden sie sich gerne vertrauensvoll an uns! Unsere zertifizierten IT-Spezialisten kümmern sich um alle Arten von PC-Problemen und bieten eine Reihe an Dienstleistungen an:
Kontaktieren Sie uns ganz einfach rund um die Uhr per:
Wir freuen uns auf Ihre Kontaktaufnahme!

Im ersten Teil unseres Artikels zum Thema Cloud-Computing haben wir bereits die verschiedenen Arten von Clouds und deren technische Realisierung gesprochen. Im heutigen Beitrag soll es um die Vor- und Nachteile und rechtliche Fragen, die bei der Nutzung solcher Dienste auftreten, gehen.
Wie in unserem Artikel zum Thema Datensicherheit und Datenschutz näher erklärt, ist in rechtlicher Hinsicht zu beachten, dass ein vollständiger und den gesetzlichen Richtlinien entsprechender Datenschutz nur durch eine technisch vollständig erfüllte Datensicherheit erreicht werden kann.
Da in Deutschland (beziehungsweise allgemeiner in der Europäischen Union) ein weitaus strikterer Datenschutz gilt als es in den USA der Fall ist, ist der Datenschutz für Cloud-Dienstleister und deren Nutzer ein heikles und teils unübersichtliches Thema. Denn gut 90 % aller Cloud-Rechenzentren stehen in den Vereinigten Staaten.
Damit unterstehen die Dienstleister (wie zum Beispiel Google, Apple oder Amazon) dem amerikanischen Recht und damit dem sogenannten Patriot Act. Dieser besagt, dass die Firmen auch personenbezogene Daten an staatliche Behörden (beispielsweise die NSA) weitergeben müssen. Ein Datenschutz nach deutschem beziehungsweise europäischen Recht ist damit nicht gewährleistet und kann unter Umständen zu Bußgeldern für die Kunden von Cloud-Anbietern führen, wenn personenbezogene Daten der Nutzer über den Clouddienstleister an amerikanische Behörden weitergegeben werden.
Ebenfalls zu beachten ist das Urheberrecht beim Speichern von urheberrechtlich geschützten Medien in einer Cloud. Prinzipiell stellt dieses Speichern eine Vervielfältigung dar und ist damit rechtswidrig, solange die Erlaubnis des Urhebers nicht eingeholt wurde und die Daten nicht für rein private Nutzen gespeichert werden.
Um den genannten rechtlichen Problemen entgegenzutreten hat sich im Jahr 2010 die Institution cloud services made in Germany gegründet, die ihre Dienste in Einklang mit geltendem deutschen Recht anbieten. Diese umfassen nicht nur CRM-Systeme, sondern auch Lösungen für Zeiterfassung, Terminverwaltung oder Personaleinsatzplanung. Die Server dieser Anbieter stehen in Deutschland und es wird die DSGVO und das deutsche Datenschutzgesetz angewandt.
Zu den großen Vorteilen des Cloud-Computings gehört sicherlich, dass sich die benötigte Hardware stark in Grenzen hält, da letztlich nur ein Endgerät von Nöten ist und nicht die gesamte Serverstruktur. Außerdem kann in den meisten Fällen von fast überall her über das Internet auf die Daten oder die Anwendungen in der Cloud zugegriffen werden – das zu jeder Tages- und Nachtzeit.
Einhergehend mit der Online-Speicherung geht auch die Sicherheit vor Datenverlust. Werden die Daten lokal gespeichert, besteht immer die Gefahr, dass die Daten bei einer Beschädigung des Speichermediums verloren gehen. Um dieses Manko auszugleichen müssten Konzepte zur Datensicherung und für Backups angewandt werden, welche bei einer Cloud-Lösung meistens vom Dienstleister mit angeboten werden. Man muss ich also auch um solche alltäglichen Probleme nicht kümmern.
Weiterhin sind bei den meisten Cloud-Lösungen keinerlei Softwareinstallationen auf dem lokalen Rechner nötig. Damit entfallen natürlich auch Wartungsarbeiten, Updates und dergleichen. Diese Dinge werden ebenfalls vom Dienstleister übernommen.
Ob sich eine Cloud für ein Unternehmen rentiert, ist ein Rechenspiel. Man muss die Kosten für den Dienstleister gegenüber dem Kauf (oder der Mietung) der Hardware abwägen und weiterhin beachten, dass auch Wartung und Instandhaltung nicht nur mit Arbeitskraft, sondern auch mit Arbeitszeit und damit Geld verbunden ist. Außerdem kann man sich bei einer Cloud-Lösung zumindest für diesen Bereich Personal einsparen.
Neben den großen Vorteilen gibt es aber auch eine Reihe an klaren Nachteilen, die nicht zu unterschätzen sind. So ist ganz grundlegend: Kein Internet, keine Arbeit. Sollte also die Internetverbindung unterbrochen sein, kann auch kein Zugriff auf die Cloud und damit auf die Dateien und die Anwendungen erfolgen. Seitens der Dienstanbieter wird in den allermeisten Fällen technisch für einen Stromausfall oder dergleichen vorgesorgt, doch hat der Kunde kein Internet, liegt die Arbeit unter Umständen brach.
Ein weiterer Nachteil in Bezug auf das Internet ist, dass der Kunde auch eine erhebliche Bandbreite benötigt, um die Daten und Anwendungen vernünftig nutzen zu können. Da selbst einfache Arbeiten wie das Erstellen einer PowerPoint-Präsentation über das Internet abgewickelt werden, wird der Kunde in hohem Maße vom Internetdienstleister abhängig.
Wie bereits erwähnt stehen die meisten Server von Cloudanbietern wie Amazon oder Google in den USA. Durch den sogenannten Patriot Act sind diese amerikanischen Firmen dazu verpflichtet, Daten ihrer Kunden an die US-Regierung weiterzugeben, selbst wenn diese auf Servern gespeichert sind, die gar nicht auf amerikanischem Territorium stehen. Das bedeutet, dass alle Daten, auf Hardware von amerikanischen Firmen gespeichert werden, an die amerikanische. Regierung weitergeleitet werden dürfen (nach amerikanischem Recht), selbst wenn der fragliche Server in Frankfurt oder München steht. Der Serverstandort ist also kein Garant dafür, dass das geltende Recht des Standortlandes auch angewandt wird. Inwieweit dies für Industriespionage ausgenutzt wird, bleibt den Kunden verborgen und gerade Firmenkunden sind gut beraten, sich dieser Tatsache bewusst zu sein.
Durch die dauerhafte Anbindung an externe Hardware über das Internet erhöht sich zwangsläufig auch die Gefahr durch Hackerangriffe und andere Angriffe über das Internet. Dieses Risiko erhöht sich in manchen Belangen unnötigerweise, da einige Anwendungen, die bei einer Cloud-Lösung über das Internet laufen, prinzipiell auch ohne diese Schnittstelle möglich wären.
Gerade für kleine Unternehmen stellt sich an einem gewissen Punkt der Firmenentwicklung die Frage, ob sie auf eine Cloud-Lösung setzen oder doch eher „offline“ arbeiten wollen. Gerade wenn eine Firma bereits mehrere Standorte hat werden die Vorteile einer Cloudlösung immer schwerwiegender, da so die einzelnen Mitarbeiter unterschiedlicher Büros sehr leicht miteinander zusammenarbeiten können.
Hat die Firma allerdings nur einen Firmensitz, stellt sich die Frage, ob ein eigenes, lokales Severnetzwerk eventuell eine bessere Lösung darstellt. Man muss dabei immer abwägen, was die jeweiligen Anforderungen an ein Firmennetzwerk sind und welche Lösung am sinnvollsten ist. Geht es ausschließlich um den Austausch von Daten, ist ein eigener Server ratsam, sollen aber auch Softwareanwendungen dezentral (also nicht auf dem lokalen Rechner der Nutzer) verwendet werden, kommt man kaum um eine Cloud herum.
Ob eine Cloud-Lösung für eine Firma (oder Privatpersonen) sinnvoll ist, muss die jeweilige Institution natürlich selbst abwägen. Kosten und Nutzen, Sicherheitsfragen, Abhängigkeiten und die dezentrale Abwicklung von Abläufen und Geschäften müssen überdacht und eventuell sogar angepasst werden. Trotz gewisser Risiken und Gefahren birgt eine Cloud-Lösung aber vor allem für kleine und mittelständische einige Vorteile, die mitunter wirtschaftlich entscheidend sein können.
Als Münchner IT-Dienstleister sind wir auch Spzialisten für Cloud-Lösungen und bieten Problembehandlung für diesen Bereich an. Unsere qualifizierten IT-Spezialisten helfen Ihnen gerne bei Ihren Problemen weiter! Folgende Bereiche gehören zu unserem Leistungsportfolio:
Vereinbaren Sie mit uns unverbindlich ein erstes Beratungsgespräch. Gerne können Sie uns eine Anfrage per E-Mail an This email address is being protected from spambots. You need JavaScript enabled to view it. senden oder uns jederzeit unter der Rufnummer 0176 / 75 19 18 18 erreichen. Wir freuen uns auf Ihre Kontaktaufnahme!

Über den Begriff Cloud stolpert man immer häufiger, vor allem, da mittlerweile so ziemlich jede Internetfirma eine eigene solche Plattform anbietet. Angefangen bei Google über Microsoft bis hin zu Amazon und Apple gibt es zig verschiedene Lösungen, mit denen man arbeiten kann. Aber was genau ist denn nun so eine Cloud? Welche Varianten gibt es? Wie funktionieren sie? Und ist es besser offline zu arbeiten oder doch lieber offline? Im ersten Teil dieser Artikelreihe klären wir zunächst, was eine Cloud ist, welche Typen es gibt, wie sie aufgebaut ist und welche Bedeutung sie in der heutigen Wirtschaftswelt hat.
Was ist eine Cloud?
Eine Cloud ist eine IT-Infrastruktur, die meist über das Internet angeboten wird und in der Speicherplatz, Rechenleistung und Anwendungen als Dienstleistung angeboten werden. Dies bedeutet aus technischer Sicht in erster Linie, dass die Arbeitsprozesse nicht an einem lokalen Rechner beim Anwender vor Ort ablaufen, sondern auf der Hardware des Anbieters. Somit entfallen für den Benutzer die Softwareinstallation und das verwendete Endgerät benötigt unter Umständen bei weitem weniger Rechenleistung und ist damit kostengünstiger.
Viele Anbieter (wie beispielsweise Google mit Google Drive) bieten für Privatnutzer in erster Linie Cloudspeicher an. Hiermit können persönliche Dateien wie Bilder, Dokumente oder Sounddateien in der Cloud gespeichert werden. Das Prinzip des Cloud-Computings geht allerdings weit über diese reine Speicherplatzauslagerung hinaus.
Google bietet beispielsweise die Möglichkeit an, die Dateien direkt im Browser (und damit ohne einen vorherigen Download) zu bearbeiten. Diese Webanwendungen bieten häufig ähnlich umfangreiche Möglichkeiten wie ihre auf dem Rechner installierten Pendants.
Im großen Maße dienen Clouds allerdings der Zusammenarbeit sehr vieler Menschen (zum Beispiel in einem Unternehmen), ohne dass jeder einzelne die Software auf seinem Rechner installiert haben muss.
Welche Arten von Clouds gibt es und was unterscheidet sie?
Nach der Definition des amerikanischen National Institute of Standards and Technology (NIST) gibt es drei verschiedene Servicemodelle und vier Liefermodelle.
Servicemodelle
Liefermodelle
Die Unterschiede zwischen den einzelnen Varianten der Clouds liegen also in erster Linie in der Art der Bereitstellung und der Art und Weise, wie die Dienste in Anspruch genommen, bezahlt und verwaltet werden können.
Technische Realisierung – Wie ist eine Cloud aufgebaut?
Die bereits weiter oben beschriebenen drei Servicemodelle des Cloud-Computing stellen gleichzeitig eine grundlegende Möglichkeit dar, eine Cloud technisch zu organisieren. Man muss sich eine Cloud also als dreiteilige Pyramide vorstellen, in der höhere Ebenen auf den unteren aufbauen, aber nicht unbedingt vorhanden sein müssen.
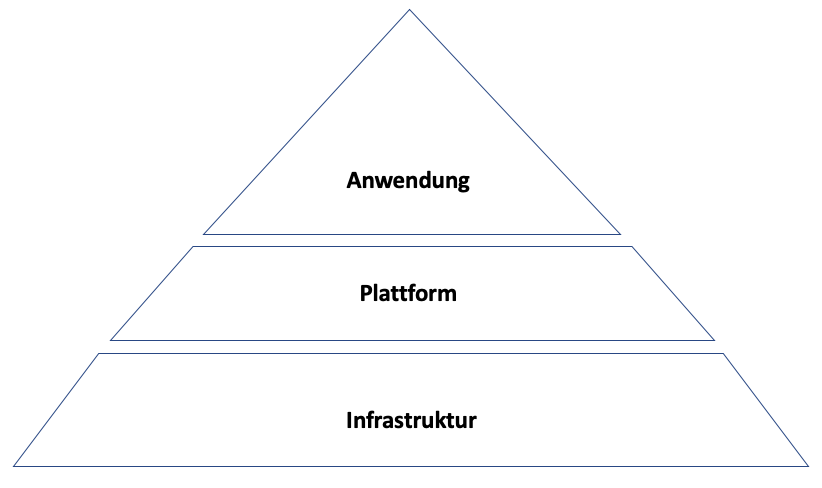
So basiert jede Cloud selbstverständlich auf der Hardware-Infrastruktur (unterste Ebene). Ein Vorteil der Arbeit auf dieser Ebene ist, dass die Recheninstanzen je nach Anforderung mehr oder weniger beliebig skaliert oder um weitere Instanzen erweitert werden können. Dabei hat der Benutzer vollständigen Zugriff auf die verschiedenen Instanzen und ist ab der Ebene des Betriebssystems selbst dafür verantwortlich.
Die zweite Ebene der Cloud Pyramide besteht aus der Plattform. Der Unterschied zur Infrastruktur-Ebene liegt darin, dass der Nutzer keinen direkten Zugriff mehr auf die Recheninstanzen hat, sondern nur innerhalb des gesteckten Rahmens sämtliche Einheiten und Unterteilungen verwaltet. Daraus folgt, dass der Cloud-Dienstleister die tatsächlich arbeitenden Instanzen nach Belieben vergrößern oder erweitern kann. Für den Kunden ist diese Abstraktion der technischen Komponente von Vorteil, wenn die Benutzer der Cloud lediglich Daten verarbeiten und nicht die technische Basis an sich administrieren sollen.
Die oberste Ebene der Pyramide stellen die Anwendungen (also die Software) dar. Auf dieser Ebene muss sich der Nutzer weder um die technischen Komponenten noch um die Skalierbarkeit des Systems kümmern. In erster Linie dient diese Ebene der Anwendung von Software durch den jeweiligen Nutzer. Diese Form der Cloud ist die unter Privatanwendern am weitesten verbreitete. Bekannte Beispiele sind Google Drive, Microsoft OneDrive oder Apple iCloud.
Cloud-Computing in der Wirtschaft
Vor allem in der Wirtschaft ist das Cloud-Computing mittlerweile stark verankert. Sie bieten großen Unternehmen weitreichende Möglichkeiten sich zu vernetzen und ihre Arbeitsabläufe den heutigen Anforderungen anzupassen. In erster Linie spart man eine Menge Kosten ein, da lokal weitaus weniger Soft- und Hardware von Nöten sind, wenn man mit einer Cloud-Lösung arbeitet.
Ein weiterer Vorteil der abstrahierten Infrastruktur einer Cloud ist, dass man Leistungsspitzen durch das dynamische Hinzuschalten von Rechenleistung leichter ausgleichen kann als mit herkömmlichen Systemen, bei denen immer genug Kapazität vorhanden sein muss, selbst wenn diese gerade nicht benötigt wird. Dadurch, dass nicht durchgängig diese Infrastruktur bereitgehalten werden muss, kann ein Unternehmen enorme Kosten einsparen.
Problematisch bei Cloud-Anwendungen ist in erster Linie die Sicherheit der Daten bei der Übertragung über das Internet. Hier hat die Weiterentwicklung der Verschlüsselungstechnologie, Probleme behoben, allerdings bestehen nach wie vor Risiken. Weiterhin ist zu beachten, dass es in vielen Fällen keine eindeutige Lösung für den Fall gibt, dass der Cloud-Anbieter oder ein beteiligter Dienstleister insolvent gehen. Was passiert dann mit den Daten? Sind sie verloren oder können sie noch gesichert werden? Manche Dienstleister bieten für solch einen Fall bereits eine Datenrücksicherung an.
Ein anderer großer, wenn auch nicht technischer, Nachteil ist, dass sich ein Unternehmen mit der Nutzung einer Cloud von dessen Anbieter abhängig macht. Nicht nur die bereits erwähnte Frage, was bei einer Insolvenz eines Anbieters geschieht, sondern auch die Tatsache, dass die Softwarehersteller durch die Endbenutzer-Lizenzvereinbarungen die Zugangsberechtigung zur Software jederzeit entziehen können. Dadurch sind die Kunden diesen Unternehmen schutzlos ausgeliefert. Solch ein Fall wurde beispielsweise 2018 publik, als Adobe kurzerhand die Lizenzen älterer Software aus ihrer Cloud als ungültig erklärte und mit rechtlichen Maßnahmen drohte, sollte man die Software weiterhin verwenden.
Im zweiten Teil dieses Artikels gehen wir näher auf rechtliche Fragen, die Vor- und Nachteile von Cloud-Computing ein und vergleichen diese moderne Arbeitsform mit der klassischen Arbeit „offline“.
Sie suchen einen zuverlässigen IT-Spezialisten für Cloud-Computing?
Als IT-Dienstleister in München bieten wir Ihnen eine Top-Beratung im Bereich Cloudanwendungen und -computing an. Wir helfen Ihnen ihre eigene Cloud-Infrastruktur aufzubauen, zu erneuern, erweitern oder zu warten. Gerne besprechen wir mit Ihnen die Unternehmenslösungen die für sie in Frage kommen. Folgende Bereiche gehören zu unserem Leistungsportfolio:
Vereinbaren Sie mit uns unverbindlich ein erstes Beratungsgespräch. Gerne können Sie uns eine Anfrage per E-Mail an This email address is being protected from spambots. You need JavaScript enabled to view it. senden oder uns jederzeit unter der Rufnummer 0176 / 75 19 18 18 erreichen. Wir freuen uns auf Ihre Kontaktaufnahme!

Keine moderne Firma und die wenigsten heutigen Haushalte kommen noch ohne einen Drucker oder ein Multifuktionsgerät mit Kopierer und Scanner aus. Da mit den Jahren die Preise für privat nutzbare Drucker immer weiter gefallen sind, kann sich jeder einen Drucker für daheim leisten und seine Dokumente oder die Bilder vom letzten Urlaub selbst ausdrucken.
Im allgemeinen Sprachgebrauch werden meist Tintenstrahldrucker und Laserdrucker verwendet. Sie sind gleichzeitig die im privaten Bereich am meisten verbreiteten Druckertypen. Im Folgenden erklären wir die Unterschiede, Vor- und Nachteile sowie die Funktionsweise dieser beiden Druckervarianten.
Der Tintenstrahldrucker – ein Klassiker und günstig zu haben
Mittlerweile gibt ein breites Angebot an Tintenstrahldruckern, die weit unter 100 Euro kosten. Grundsätzlich sind hier noch einmal die CIJ-Drucker (Continuous Ink Jet = Tintenstrahldrucker) und die DOD-Drucker (Drop on Demand, Tintendrucker) zu unterscheiden.
Continuous Ink Jet (Tintenstrahldrucker)
Bei dieser Bauweise wird ein durchgängiger Tintenstrahl aus der Drüse des Druckkopfes abgesondert. Durch einen piezoelektrischen Wandler wird der Strahl so beeinflusst, dass er gleichmäßig in Tropfen zerfällt. Durch eine Ladeelektrode werden die dadurch entstandenen Tropfen elektrostatisch aufgeladen, sodass dann mittels einer Ablenkelektrode je nach angelegter Spannung unterschiedlich stark abgelenkt werden können, wodurch sich das Druckbild ergibt.
Nicht benötigte Tropfen werden bereits im Druckkopf abgefangen und zurück in den Tintenspeicher geführt, sodass keine Tinte verschwendet wird oder unerwünschte Tropfen auf das Papier gelangen.
Drop on Demand (Tintendrucker)
Dieser Druckertyp findet in einem sehr weit gefächerten Bereich Anwendung. Von Passbildern über den Bürobereich bis hin zur industriellen Nutzung werden die verschiedensten Bereiche abgedeckt. Neben Tinte können bestimmte Geräte mit dem DOD-Verfahren auch Wachs, Kunststoffe oder Lote als Druckmaterial verwenden, sodass damit sogar elektrische Schaltungen oder dreidimensionale Objekte gedruckt werden können.
Die verschiedenen Hersteller verwenden wiederum unterschiedlichste Bauweisen für ihre Druckköpfe und deren Drüsen, die allerdings hier nicht näher erläutert werden sollen. Allen gemeinsam ist allerdings, dass die Druckköpfe regelmäßig gereinigt werden müssen, da Tintenrückstände eintrocknen und so die Druckdrüsen verstopfen können. Um dies zu verhindern werden verschiedene Mechanismen angewandt. Beispielsweise wird der Druckkopf immer vor dem ersten Druckdurchlauf gereinigt. Andere Modelle verschließen den Druckkopf luftdicht, ähnlich der Kappe auf einem Füllfederhalter.
Tinte und Spezialpapiere
Wie bereits erwähnt sind Tintenstrahldrucker empfindlich gegenüber dem zu bedruckenden Papier. Erst auf Spezialpapieren erreichen sie ihre volle Qualität. Diese Papiere (die auch aus speziellen Kunststoffen bestehen können) unterscheiden sich in erster Linie in ihrer Struktur und der damit verbundenen Art und Weise, wie stark die Tinte innerhalb des Papiers verläuft.
Die meisten Tinten werden auf Wasserbasis hergestellt. Wichtig für CIJ-Drucker ist, dass die hier verwendete Tinte elektrisch leitend ist, da ansonsten der piezoeletrische Effekt nicht greifen kann und damit das gesamte Konzept des Tintenstrahldruckers hinfällig wird. Grundsätzlich unterscheiden sich die Tinten dadurch, ob die farbgebenden Stoffe in der Tinte gelöst sind (Farbstoffstinten) oder als Pigmente in der Tinte vorhanden sind (Pigmenttinten).
Der Laserdrucker – die moderne Alternative
Im Gegensatz zu Tintenstrahldruckern, bei denen das Druckverfahren bereits im Namen steckt, besagt das „Laser“ in Laserdrucker nicht, wie die Farbe auf das Papier gebannt wird. Vielmehr dient der Laser dazu, ein Abbild zu erstellen, mit dem dann die Farbe auf das Papier aufgetragen wird.
Aber der Reihe nach. Ein Laserdrucker zählt zu den sogenannten Seitendrucker, da die Belichtung der der Druck der gesamten Seite in einem einzigen Durchlauf geschehen. Er nutzt genauso wie Fotokopierer das Elektrofotografie-Prinzip.
Bei diesem Prinzip wird die Bildtrommel des Laserdruckers elektrisch aufgeladen. Dies geschieht bei älteren Modellen mittels einer sogenannten Ladekorona oder heutzutage mittels einer Ladungswalze, die die Bildtrommel direkt berührt und die elektrische Ladung direkt überträgt. Der große Vorteil des neueren Verfahrens ist, dass aufgrund der direkten Übertragung der Ladungen der Sauerstoff (O2) der Luft nicht mehr zu Ozon (O3) ionisiert wird und es damit weitaus umweltfreundlicher und weniger gesundheitsgefährdend ist.
Nach der Aufladung der mit einem Fotoleiter (sogenannte Phthalocyanine) beschichteten Bildtrommel erfolgt die Belichtung durch den namensgebenden Laser. Dort, wo das Licht des Lasers auf die Bildtrommel fällt, wird die Trommel wieder entladen. An diesen entladenen Stellen bleibt später der Toner hängen. Je stärker die Belichtung an einer Stelle ist, desto mehr Toner wird dort auch haften bleiben. Anschließend erfolgt die Entwicklung, bei der die auf der Bildtrommel verbleibende Ladung den Toner anzieht.
Im nächsten Schritt wird das zu bedruckende Papier zwischen die Bildtrommel und eine entgegengesetzt geladene Transferrolle gezogen. Die Ladung der Transferrolle zieht den Toner von der Bildtrommel zu sich hin, wodurch das Abbild, das im ersten Schritt auf die Bildtrommel aufgetragen wurde, nun in Form des Toners auf das Papier übertragen wird.
Nun muss das Tonerpulver noch fest mit dem Papier verbunden werden. Dies geschieht mittels Druck und Hitze (ca. 180 Grad Celsius) zwischen zwei weiteren Walzen. Dadurch verschmilzt der Toner mit dem Papier und das fertige Endprodukt wird ausgegeben.
Tintenstrahldrucker vs. Laserdrucker – was sind die Vor- und Nachteile?
Der Einfachheit halber sollen hier die Vor- und Nachteile eines Laserdruckers beschrieben werden – die Vorteile des Laserdrucks sind dementsprechend die Nachteile des Tintenstrahldrucks.
Die Vorteile eines Laserdruckers fangen bei bei der meist höheren Ausgaberate von bis zu 500 Seiten pro Minute an. Diese hängt natürlich stark vom jeweiligen Gerät ab. Bei reinem Textdruck und geschäftlichen Grafiken sind Laserdrucker in der Druckqualität unerreicht. Die gedruckten Konturen bluten nur gering aus und der Toner ist gegenüber Sonneneinstrahlung und Wasserkontakt beständiger als Drucke aus einem Tintenstrahldrucker. Weiterhin ist ein Laserdrucker weniger empfindliche gegenüber verschiedenen Papiersorten.
Neben diesen qualitativen Vorteilen weisen Laserdrucker auch rein praktische Vorteile auf. So sind beispielsweise die Druckkosten geringer, die Lebenserwartung der Gerät ist höher und der Wartungsaufwand fällt geringer aus, da die Tonerkartusche nicht verstopft, wenn längere Zeit nicht gedruckt wurde, wie es bei Tintenpatronen häufig der Fall ist.
Trotzdem gibt es natürlich auch einige Nachteile. So sind Laserdrucker für den Druck von Bilder nicht so gut geeignet. Zwar ist das Bild wischfest, allerdings nicht resistent gegenüber Knicken. Dabei können Teile des Toners sogar abblättern. Bei reinem Text ist dies nicht der Fall. Im Gegensatz zum Tintenstrahldrucker kann der Druckvorgang beim Laserdrucker nicht abgebrochen werden, da er wie bereits erwähnt zu den Seitendruckern gehört.
Beim Laserdruck kann die für das Verschmelzen des Toners notwendige Hitze ein Problem darstellen. So stellt das Bedrucken von Folien eine gewisse Herausforderung dar und benötigt Spezialfolien. Bei älteren Geräten mit einer Ladekorona entsteht zudem gesundheitsschädliches Ozon. Auch der Toner ist potenziell gesundheitsgefährdend und muss als Sondermüll entsorgt werden, was allerdings auch auf die Patronen eines Tintenstrahldruckers zutrifft.
Zusammenfassend lässt sich also sagen, dass vor allem beim Textdruck und Drucken im einfachen Büroumfeld Laserdrucker zu empfehlen sind, während Tintenstrahldrucker eher bei aufwendigen Bilddrucken ihre Vorteile ausspielen können. Da die meisten Drucker aber im Büro Verwendung finden und auch die meisten Kopierer mit Laserdrucktechnologie arbeiten, sind in diesem Bereich ebenfalls Laserdrucker beziehungsweise Multifunktionsgeräte zu empfehlen.
Probleme mit Ihrem Drucker?
Bei technischen Problemen mit Ihrem Drucker können wir Ihnen gerne weiterhelfen. Als IT-Dienstleister, gehört die Konfiguration, der Anschluss oder die Wartung ihrer Geräte wie Drucker zu unseren täglichen Aufgaben. Unsere zertifizierten IT-Spezialisten kümmern sich gerne um Ihr Problem!
Kontaktieren Sie uns noch heute!

Am 3. August 1984 wurde in Deutschland die allererste E-Mail empfangen. Verschickt worden war sie einen Tag zuvor in den Vereinigten Staaten von Amerika. Was damals über ein Vorläufersystem des Internets im Rahmen einer Kooperation zwischen amerikanischen und deutschen Universitäten verschickt wurde, hat bis zum heutigen Tag die Arbeitsweise der meisten Firmen revolutioniert. Was früher per Post und Telegramm mehrere Tage dauern konnte, wird heute in Sekundenbruchteilen abgearbeitet.
Während die E-Mail im Arbeits- und Privatleben mittlerweile nicht mehr wegzudenken ist, stellen mit der schieren Masse an versandten und empfangenen Mails immer größere Herausforderungen. Um diesen Datenmengen Herr zu werden gibt es einige ganze Reihe an Möglichkeiten, wie man diese archivieren kann. Dabei gilt es aber einiges zu beachten.
Wozu benötigt man eine E-Mail-Archivierung?
Seit die E-Mail die meisten anderen Kommunikationsplattformen wie Telefon, Fax und Post überholt hat, ist sie für die meisten Firmen absolut unabdingbar geworden. Jährlich werden Milliarden von Mails verschickt und mit ihnen Dokumente, Medien, Rechnungen und weiter Anhänge mehr. Diese sensiblen Dateien müssen alleine schon aus rechtlichen und steuerlichen Gründen regelmäßig und lückenlos archiviert werden.
Weiterhin sieht die Rechtslage in Deutschland vor, dass diese Daten manipulationssicher abgespeichert werden müssen. Das heißt, dass die enthaltenen Dokumente im Nachhinein nicht mehr verändert werden dürfen. Ähnliches gilt bereits für nicht-digitale Dokumente wie Rechnungen oder Urkunden.
Daneben gibt es auch rein praktische Gründe. So werden die Inhalte der E-Mails durch eine Archivierung vor Verlust geschützt. Die Archivierung dient also der Datensicherung. Über die verschiedenen Möglichkeiten einer Datensicherung im Allgemeinen können Sie in unserem Artikel dazu nachlesen.
Desweiteren kann durch eine Archivierung die Belastung des E-Mail-Servers reduziert werden, was gerade in großen Unternehmen mit einer enormen Anzahl an E-Mail-Accounts und versandten Nachrichten relevant ist.
Welche Arten der E-Mail-Archivierung gibt es und was unterscheidet sie?
Grundlegend kann man zwei Arten der Archivierung unterscheiden: die serverseitige und die clientseitige.
Bei ersterer Variante werden sämtliche eingehenden und ausgehenden Mails automatisiert archiviert. Dadurch werden sämtliche Mails und Dokumente manipulationssicher in das Archiv übertragen. Damit im Archiv selbst keine Manipulationen mehr möglich sind, müssen hierfür allerdings weitere Sicherheitsmaßnahmen getroffen werden. Diese Methode hat einen relativ hohen Speicherbedarf, weshalb eine gute Sortierung der Mails unabdingbar ist, damit beispielsweise keine großen Mengen an Spam-Mails mit archiviert werden.
Wichtig hierbei ist ein gut funktionierender Spamfilter, um zu verhindern, dass wichtige Daten aus Versehen gelöscht werden, die ungewollt als Spam markiert worden sind. Außerdem muss darauf geachtet werden, dass keine Mails archiviert werden, die aus rechtlichen Gründen nicht in das Archiv integriert werden dürfen. Dies ist aus datenschutztechnischen Gründen bei privaten E-Mails der Fall. Für diese Anforderungen werden meist serverseitige Konzepte angewandt, den Inhalt der Mails nach definierten Regeln analysieren und filtern, bevor sie archiviert werden. Diese Konzepte sind durch Softwarelösungen sehr gut an die individuellen Anforderungen der Firmen oder Privatpersonen anpassbar.
Ein weiterer Vorteil der serverseitigen Archivierung ist, dass das Suchen nach oder in älteren E-Mails nicht mehr über den E-Mail-Server laufen, sondern direkt im Archiv abgewickelt werden kann.
Die clientseitige Archivierung hingegen findet nicht automatisiert statt, sondern wird durch den Anwender direkt gesteuert. Dabei sortiert der User die E-Mails selbst und verschiebt sie manuell in das jeweilige Archiv. Dadurch bietet diese Methode einen hohen Grad an Flexibilität, allerdings birgt sie auch die Gefahr, dass relevante Mails aus Versehen archiviert oder gelöscht werden. Hierbei ist das menschliche Fehlerpotenzial recht hoch, während bei der serverseitigen Archivierung eher systematische Fehler auftreten können.
Gerade im geschäftlichen Bereich und bei großen Datenmengen ist also eine serverseitige Archivierung zu empfehlen, da hierbei einerseits Fehlerquellen minimiert werden und zum anderen eine rechtssichere Archivierung gewährleistet werden kann.
Mittlerweile gibt es eine ganze Reihe an Anbietern, die verschiedene Varianten der E-Mail-Archivierung anbieten. Application Service Provider (ASP) beispielsweise bieten E-Mail-Datenmanegement-Funktionen an, die keinerlei clientseitigen Programme erfordern und ausschließlich serverseitig arbeiten.
Stand-Alone-Lösungen hingegen sind Anwendungen, die sowohl client- oder serverseitig arbeiten können. Hierbei kann entweder der Anwender selbst entscheiden, welche E-Mails wie archiviert werden sollen oder er gibt Einstellungen vor, die dann vom Programm automatisiert befolgt werden.
Neben diesen Möglichkeiten der E-Mail-Archivierung gibt es auch einige Lösungen, die von Anbietern stammen, die bereits Dokumentmanagementsysteme oder CRM-Anwendungen (Customer Relationship Management) vertreiben. Diese Systeme arbeiten im Vergleich zu ASP-Lösungen umfangreicher und werden über eine clientseitige Anwendung verwaltet.
Isolierte Archivierung vs. E-Mail-Management
Die rein isolierte Archivierung von E-Mails steht immer wieder in der Kritik, da Bezüge zu anderen, relevanten Informationen oft nicht gewährleistet werden können. So sind die Inhalte von Geschäfts-E-Mails oft abhängig von vorausgegangen Besprechungen, die in einem Protokoll festgehalten worden sind. Da dieses Protokoll im Normalfall aber nicht immer im Anhang steht (bei größeren und längeren Projekten würde das den Umfang von Anhängen weit überschreiten), stehen die E-Mails für sich alleine und können nicht ausreichend in das Gesamtnetz an Informationen innerhalb einer Firma integriert werden.
Deshalb setzt sich immer das sogenannte E-Mail-Management durch, das den Sachzusammenhang zwischen den E-Mails und anderen elektronischen Dokumenten herstellen kann. Bei diesem Verfahren werden die Mails nicht in Abhängigkeit ihrer Form abgespeichert, sondern erfüllen auch andere Kriterien, beispielsweise die Speicherung nach Nutzen oder Rechtscharakter.
In diesen Managementsystemen werden die Mails an ein elektronisches Archivsystem übergeben, in der auch andere Datensätze (beispielsweise Besprechungsprotokolle) unter einem gemeinsamen Index („Tag“) gespeichert sind. Dadurch werden elektronische Akten erstellt, die ähnlich ihren haptischen Pendants funktionieren und verschiedenste Dokumente und Informationen enthalten können.
E-Mail-Archivierung und das Postgeheimnis
Aus rechtlicher Sicht gilt das Postgeheimnis auch für die elektronische Form von Briefen, also die E-Mails. Ein steuerlich relevantes Dokument (beispielsweise eine Rechnung) muss also auch in digitaler Form genauso dokumentiert und gesichert werden wie ein ausgedrucktes. Dies bedeutet, dass folgende Punkte erfüllt werden müssen:
Die archivierten E-Mails müssen dabei zu jeder Zeit erreichbar sein (beispielsweise bei einer Betriebsprüfung). Zu beachten ist, dass private E-Mails nicht automatisch archiviert werden dürfen, da dies gegen das Postgeheimnis (Grundrecht, Artikel 10) verstoßen würde. Hierfür können seitens des Arbeitgebers entweder ein allgemeines Verbot privater E-Mails eingeführt werden oder eine anderweitige vertragliche Vereinbarung dieses Problem lösen.
Probleme mit ihrer Archivierung? Wir helfen gerne!
Sollten Sie Hilfe bei Ihrer E-Mail-Archivierung oder generell bei einer Datensicherung benötigen, können Sie sich gerne jederzeit bei uns telefonisch oder per Mail melden und gemeinsam lösen wir Ihr Anliegen oder Problem!
Folgende Leistungen bieten wir Ihnen im Bereich der Datensicherung jederzeit an:
Sämtliche Vorgänge werden von unseren zertifizierten IT-Profis durchgeführt.
Sie brauchen für Ihr Unternehmen eine eigens für Sie zugeschnittene Software-Lösung im Bereich der E-Mail-Archivierung? Kein Problem! Wir beraten Sie gerne über die bestehenden Möglichkeiten.

In der heutigen Informationsgesellschaft werden Begriffe wie Privatsphäre, Datenschutz und IT-Sicherheit zu omnipräsenten Themen in sämtlichen Medien. Oft werden diese Begriffe fälschlicherweise synonym verwendet und stiften so zusätzlich Verwirrung. Wir klären auf über die wichtigsten Grundzüge der häufigsten Begriffe.
Was ist Datenschutz?
Der am häufigsten auftretende Begriff mag wohl der Datenschutz sein. Spätestens seit der Datenschutzgrundverordnung (DSGVO) hört man regelmäßig in den Nachrichten vom Datenschutz und Verstöße gegen eben jenen. Seit dem 25. Mai 2018 gilt in der gesamten Europäischen Union die sogenannte DSGVO – und damit auch in Deutschland. In dieser Verordnung ist im Grunde der „Schutz der Privatsphäre natürlicher Personen bei der Verarbeitung personenbezogener Daten“ geregelt.
Da die Datenverarbeitung in den letzten Jahrzehnten immer wichtiger und vor allem einfacher wurde, brauchen wir für deren Regelung zunehmend neue Richtlinien. In erster Linie dienen diese dazu, Organisationen wie Unternehmen (beispielsweise Google) daran zu hindern, eine Monopolstellung in Sachen Datennutzung aufzubauen und das Ausufern staatlicher Überwachung einzudämmen. Des Weiteren soll verhindert werden, dass die Entwicklung hin zum gläsernen Menschen weiter voranschreitet.
Die technische Entwicklung der letzten Jahre (vor allem des Internets) hat zum einen die zu verarbeitende Datenmenge in die Höhe schießen lassen. Dadurch sind Daten zum anderen aber auch zu einem gigantischen wirtschaftlichen Gut geworden und für Großkonzerne wie Google oder Apple von immenser Bedeutung.
Generell bezeichnet der Begriff Datenschutz also das Prinzip, natürliche Personen davor zu beschützen, dass ihre Daten gegen ihren Willen an Dritte weitergegeben werden.
Was sind Datensicherheit und IT-Sicherheit?
Als Datensicherheit bezeichnet man das rein technische Ziel, Daten vor ungewolltem Zugriff zu schützen und sie vor Manipulation und Verlust zu bewahren. Hierbei spielen soziale Faktoren noch keinerlei Rolle.
Die IT-Sicherheit beschreibt in erster Linie die technischen Komponenten von Datensicherheit und Datenschutz. Im betrieblichen Rahmen sorgt sie für den Schutz vor wirtschaftlichem Schaden, beispielsweise durch Hacker-Angriffe oder die ungewollte Verbreitung betriebsinterner Daten. In das Feld der IT-Sicherheit fällt aber auch Software wie die Firewall oder der Virenscanner eines Computers. Bei der IT-Sicherheit spielen soziale Faktoren bzw. der Mensch eine wichtige Rolle. Beispielsweise berücksichtigt die IT-Sicherheit wenn möglich auch das potenzielle Verhalten der Nutzer.
In Abgrenzung dazu werden zur Informationssicherheit auch diejenigen Informationen gezählt, die nicht elektronisch verarbeitet werden, beispielsweise Handschriftliche Dokumente, die ebenfalls personenbezogene Daten beinhalten können.
Was muss ich beim Thema Datenschutz beachten?
Generell besagt die Informationelle Selbstbestimmung, dass jeder Mensch ein Recht darauf hat, selbst darüber zu entscheiden, was mit seinen personenbezogenen Daten geschieht und wer sie erhält. Daraus folgt im Prinzip, dass man personenbezogene Daten anderer Menschen nicht ohne die Einwilligung der jeweiligen Person an Dritte weitergeben werden dürfen. Genau genommen fängt dies bereits bei der privaten Telefonnummer des Freundes an, die man an ohne dessen Einwilligung an einen anderen Freund weitergibt.
Dies ist natürlich die rein rechtliche Bestimmung. Dass dies in der Praxis oft bei weitem nicht so eng gesehen wird – vor allem im privaten Bereich – ist verständlich. Aber gerade, wenn Firmen und damit große Geldmengen ins Spiel kommen, sollte man Vorsicht walten lassen. Denn generell kann man zur Rechenschaft gezogen werden, sollte man personenbezogene Daten Anderer an Dritte weitergeben.
Jeder hat das Recht, selbst darüber zu entscheiden, wie er mit seinen persönlichen Daten umgehen möchte. Ob man persönliche, möglicherweise pikante Informationen frei im Internet zirkulieren lassen möchte, muss jeder selbst entscheiden. Heutzutage ist es kein Einzelfall mehr, dass die Personalchefs von Firmen die sozialen Netzwerke ihrer potenziellen neuen Mitarbeiter genauer unter die Lupe zu nehmen. Auch wenn diese Informationen die Entscheidung der Personaler eigentlich nicht beeinflussen darf, kann man trotzdem davon ausgehen, dass sie es (wenn auch unterbewusst) tun.
Allgegenwärtig ist auch die empfundene Gefahr einer flächendeckenden Überwachung und Ausspähung durch den eigenen Staat, wie es bereits in den Vereinigten Staaten Gang und Gäbe ist. In Deutschland sieht die rechtliche Lage allerdings ein wenig anders aus. Aufgrund der Gewaltenteilung braucht es für jede ausspähende Maßnahme seitens des Staates einen richterlichen Beschluss. Die dadurch erfassten Daten und Informationen dürfen nicht auf Vorrat gespeichert werden, sondern nur in einem begründeten Verdachtsfall. Außerdem muss der Ausgespähte nach einer Frist darüber in Kenntnis gesetzt werden, dass er überwacht wurde.
Tipps zum sicheren Verhalten im Internet
Das persönliche Engagement spielt bei der Sicherheit ihrer Daten eine enorme Rolle, da sich Firmen, die Ihre Daten erlangen wollen, um sie gewinnbringend weiterverkaufen zu können, sich selbst absichern, um nicht gegen Ihr Grundrecht der Informationellen Selbstbestimmung zu verstoßen. So akzeptieren Sie durch das Annehmen einer Softwarelizenz (beispielsweise bei Windows), dass eine ganze Reihe an personenbezogenen Daten an die Herstellerfirma gesendet wird. Verweigern Sie diese Zustimmung, dürfen Sie das Produkt auch nicht verwenden.
Die Tendenz, in solchen Fällen mit unseren personenbezogenen Daten für Lizenzen und Dienstleistungen zu bezahlen wird immer stärker und ist in hohem Maße besorgniserregend, wenn auch in der heuten Informationsgesellschaft kaum mehr aus der Welt zu schaffen.
Abschließend lässt sich sagen: seien Sie sich der eigenen Verantwortung gegenüber Ihren personenbezogenen Daten bewusst und gehen Sie nicht zu sorglos mit diesen um! Man muss zwar nicht in Paranoia verfallen, allerdings ist eine gewisse Vorsicht definitiv geboten.
Im letzten Teil unserer Artikelserie behandeln wir die HDMI-Schnittstelle und sehen uns genauer an, was Bezeichnungen wie HD, UHD und HD Ready bedeuten.
Die HDMI-Schnittstelle wurde bereits Ende 2002 in ihrer ersten Version veröffentlicht. Heute finden sie HDMI-Anschlüsse an den meisten Endgeräten, vor allem aber an Desktop-PCs, Laptops, Spielekonsolen und Home Entertainment Systemen. Während sich der ebenfalls digitale Display Port Standard vor allem auf dem stationären Computermarkt etabliert hat, ist HDMI bei Unterhaltungselektronik vertreten.
HDMI unterstützt – wie die anderen modernen Videosignalstandards auch – nicht nur die Videoübertragung, sondern setzt auf eine ganze Bandbreite an möglichen Informationskanälen. So werden neben dem Bildsignal bis zu 32 Audiokanäle, Kopierschutzmechanismen (DRM) und teilweise sogar Ethernet unterstützt.
Mit der 2017 vorgestellten aktuellen Version 2.1 lassen sich Auflösungen von bis zu 8K (7680 × 4320 Pixel) bei 60 Hz Bildwiederholrate oder 4K (3840 × 2160 Pixel) bei 120 Hz erreichen. Letzteres erlaubt das Abspielen von 3D-Material in 4K-Auflösung.
Neben dem normalen HDMI-Stecker gibt es noch die beiden kompatiblen Varianten MiniHDMI und MicroHDMI, die aufgrund ihrer kompakteren Bauweise vor allem für mobile Endgeräte verwendet werden.

HD (kurz für High Definition) bedeutet im Grunde nichts anderes als „hohe Auflösung“. Mit dieser Abkürzung werden mittlerweile eine ganze Bandbreite an verschiedenen Begriffen zu Werbezwecken und Gerätebeschreibungen verwendet. Wir erklären die wichtigsten und am weitesten verbreiteten Beschreibungen.
HD-Auflösungen = setzen eine minimale Zeilenanzahl von 720 Pixeln voraus. Bei einem Seitenverhältnis von 4:3 entspricht die Spaltenanzahl 960, bei 16:9 sind es 1280 Pixel.
Full-HD = entspricht einer Auflösung von 1920x1080 Pixeln (1080p).
UHD 4K = entspricht einer Auflösung von 3840x2160 Pixeln. Da die Anzahl von Zeilen und Spalten im Vergleich zu Full-HD jeweils verdoppelt werden, ist die Pixelanzahl vervierfacht.
UHD 8K = entspricht einer Auflösung von 7680x4320 Pixeln. Im Vergleich zu Full-HD wird die Pixelanzahl versechzehnfacht.
Das Siegel HD Ready kann jeder Hersteller für seine Geräte lizenzieren, die mindestens eine Auflösung von 1280 × 720 Pixeln (720p) verarbeiten können.
Darauf aufbauend wurde 2007 das Siegel HD Ready 1080p bereitgestellt, das zusätzlich zu den Voraussetzungen von HD Ready eine höhere Auflösung von mindestens 1920x1080 Pixeln bietet (was der Bezeichnung Full-HD entspricht).
Hiermit endet unsere vierteilige Artikelserie zu Videokabeln. Im Folgenden finden Sie noch einmal die anderen Teile der Serie:
Übersicht
In den beiden vorangegangen Artikeln dieser Reihe haben wir bereits einen Überblick über die einzelnen Videokabel geben und sind genauer auf die beiden etwas älteren Video-Standards VGA und HDMI eingegangen. Im heutigen Artikel geht es um die moderneren Standards Display Port und die Multifunktionsschnittstelle Thunderbolt von Apple.
Ähnlich wie HDMI oder Thunderbolt bietet der 2006 eingeführte Standard Display Port die Möglichkeit Bild und Ton über ein Kabel zu übertragen, statt mehrere zu verwenden.
Seit circa 2016 hat der Display Port den alten Standard DVI abgelöst. Vor allem im Computerbereich, wo Monitore an die Grafikkarten der Rechner angeschlossen werden, hat sich der Display Port durchgesetzt, da er einige Vorteile gegenüber der Konkurrenz HDMI aufweist.
So bietet der Display Port beispielsweise die Möglichkeit sogenannte Daisy Chains einzurichten. Hierbei werden kompatible Monitore in Reihe geschaltet und können unabhängig voneinander angesteuert werden. Vergleichbares ist mit der HDMI-Schnittstelle nicht möglich, hierfür bräuchte man mehrere Anschlüsse, die parallel geschaltet werden.
Ein weiterer Vorteil des Display Ports ist, dass er im Vergleich zu den älteren Standards VGA und DVI eine weitaus kleinere Steckerbuchse hat, was vor allem für mobile Endgeräte wie Laptops von Vorteil ist, da diese in den letzten Jahren kleiner und vor allem dünner geworden sind.
Im Gegensatz zu HDMI und Thunderbolt besitzt der Display Port eine Verriegelungsmechanik.

Apple versucht seit 2011 mit seiner Thunderbolt-Technologie die eierlegende Wollmilchsau unter den Datenkabeln zu erschaffen – und dies gelingt dem Technologiekonzern aus Kalifornien recht gut.
Die Thunderbolt-Schnittstelle vereint Video-, Audio- und Datenübertragung sowie Peripherie in einer Schnittstelle. Technisch gesehen ist es eine Weiterentwicklung der Display Port Technologie, weshalb er zu verschiedensten anderen Kabeltypen (u.a. USB, HDMI, DP, DVI, VGA) kompatibel ist. Da Thunderbolt auch zur Energieübertragung dient, können damit beispielsweise kompatible Smartphones und andere Geräte geladen werden.
Da Thunderbolt auf dem USB Type C Stecker basiert, ist die Buchse – im Gegensatz zu älteren USB-Varianten – punktsymmetrisch, wodurch die Einsteckrichtung nicht mehr relevant ist. Durch die kompakte und kleine Bauweise und dadurch, dass viele Funktionen in einem Stecker vereint werden, eignet sich Thunderbolt vor allem für mobile Endgeräte.
Nachdem Anfang 2019 die Lizenzen für Thunderbolt an das USB Implementers Forum (USB-IF) übergeben worden wird, ist Thunderbolt lizenzfrei erhältlich. Im gleichen Zuge wurde angekündigt, dass der zukünftige USB 4 Standard auf Basis von Thunderbolt 3 entwickelt werden wird.
Im vierten und letzten Teil unserer Serie werden wir das High Definition Media Interface (HDMI) behandeln und genauer die verschiedenen Bezeichnungen HD Ready und Full HD eingehen.

|
App Anfrage 0176 75 19 18 18
Kostenfreie Erstberatung |

